Regularization and Optimization
Train / Dev / Test sets

- used to be 60/20/20%
- now it’s more like 98/1/1%.
Important
Train and dev sets should come from the same distribution.
Bias/Variance

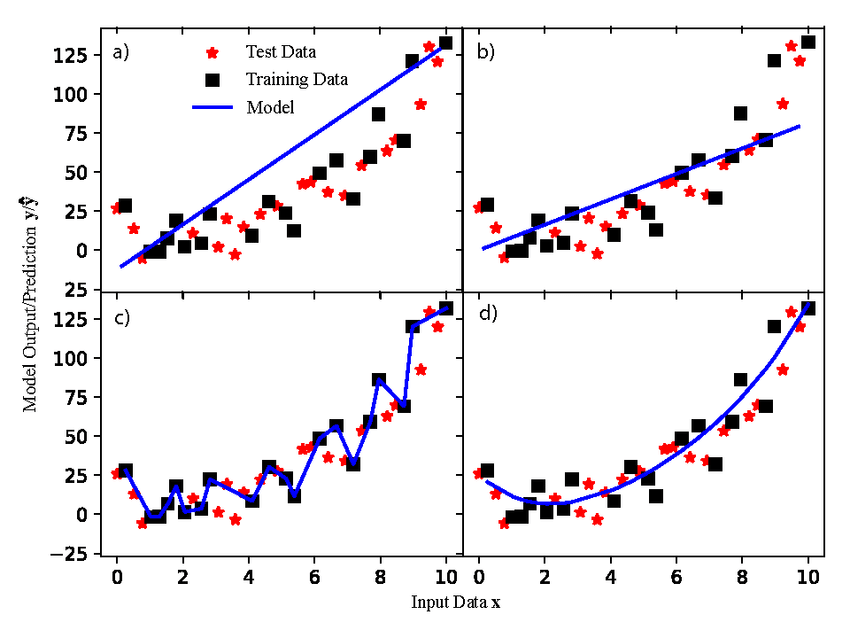
- High Bias Simple hypothesis, not able to train properly on the training set and test set both. This is Underfitting.
- High Variance. Very complex hypothesis, not able to generalise. Will perform great on training data and poor on the test data. This is Overfitting.
- Just Right: The glorious balance
Bias/Variance
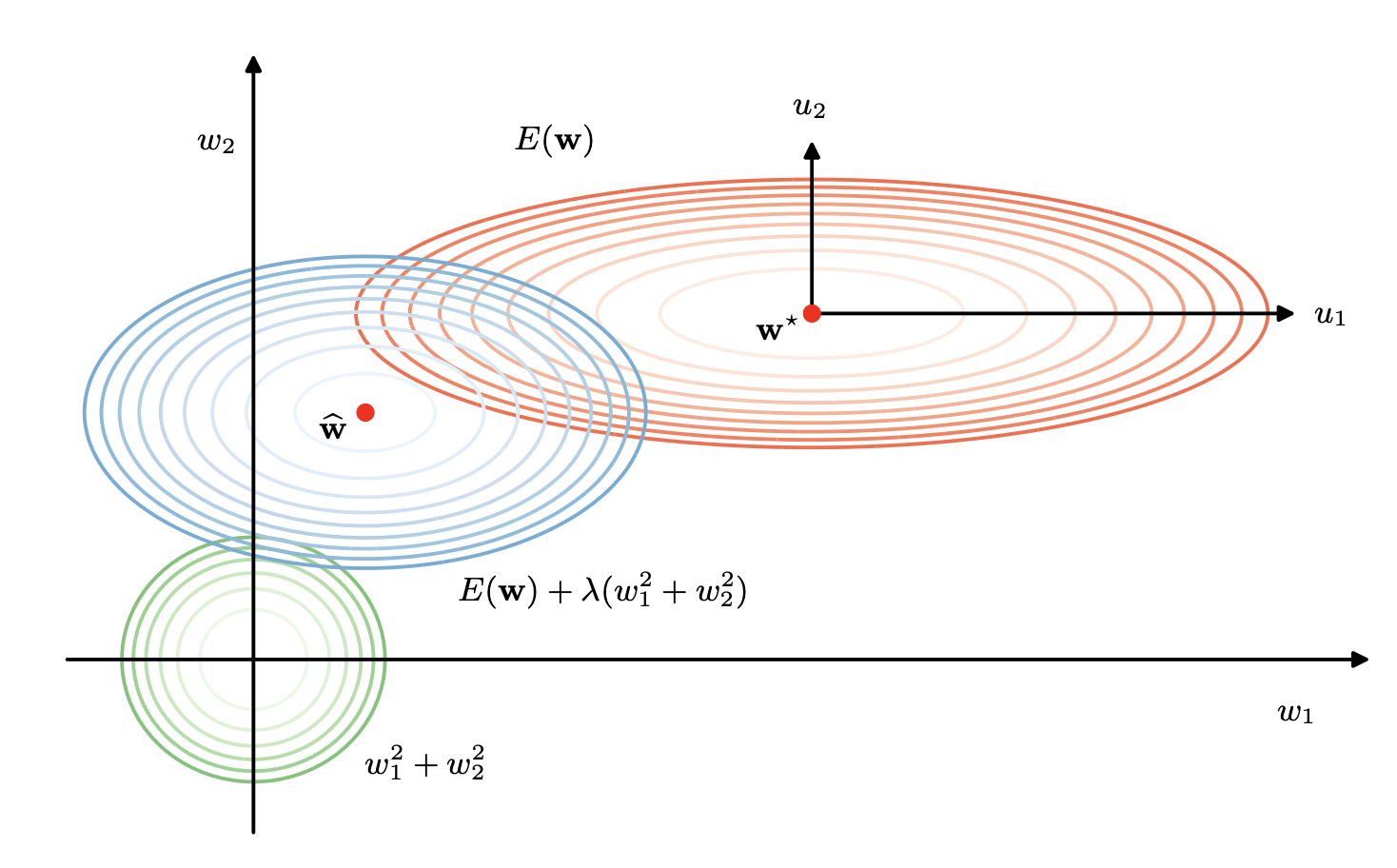
Regularization

Why Regularization Reduces Overfitting?
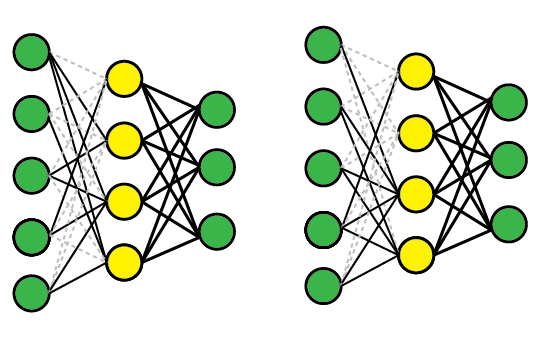
Randomized connection dropping
Aka DropConnect.
Dropout Regularization
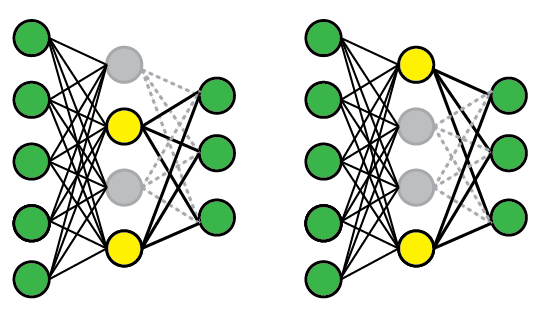
Dropout
Dropout
Dropout Regularization
Inverted dropout
Create a random matrix e.g. for layer 3:
\[\begin{align*} &d3 = np.random.randn(a3.shape[0], a3.shape[1]) < keep\_prob \\ &a3 = np.multiply(a3, d3) \\ &a3 /= keep\_prob \end{align*}\]
This ensures that the expected value of keep_prob remains the same. At test time we’re not using dropout.
Other Regularization Methods
Data augmentation
For example, flip images to generate extra training samples. Or do random distortions. 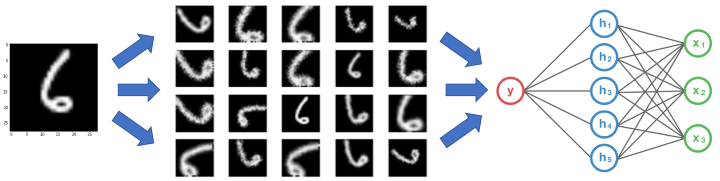
Other Regularization Methods
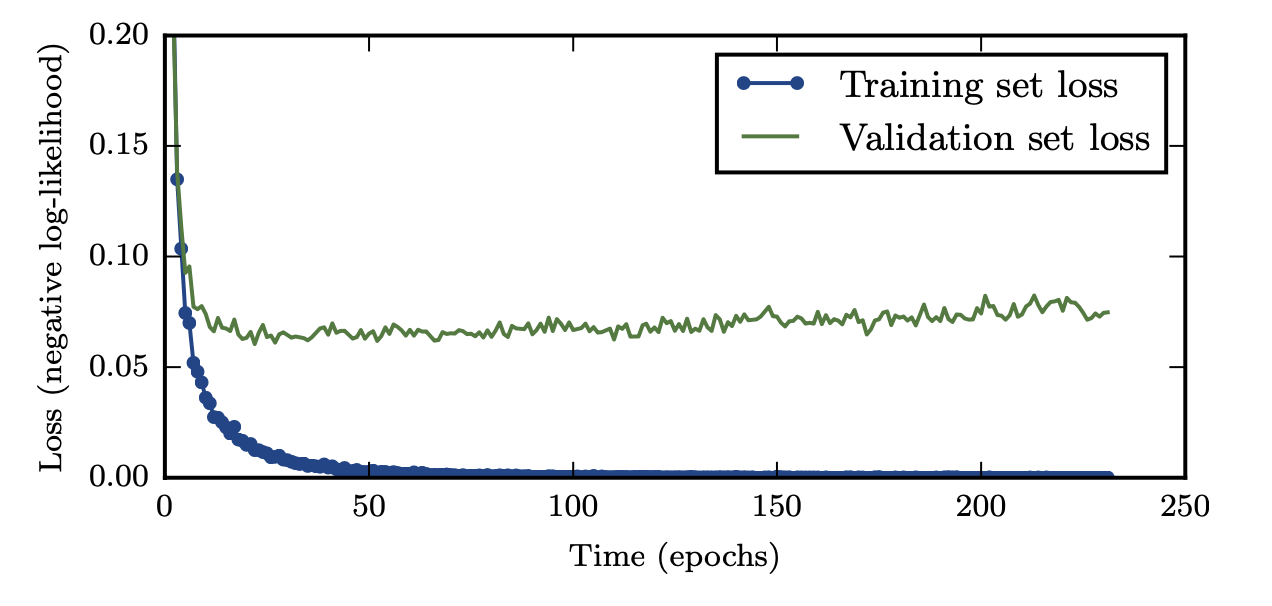
Other Regularization Methods
Noise injection: injecting a matrix of random values from a Gaussian distribution.
Normalizing inputs
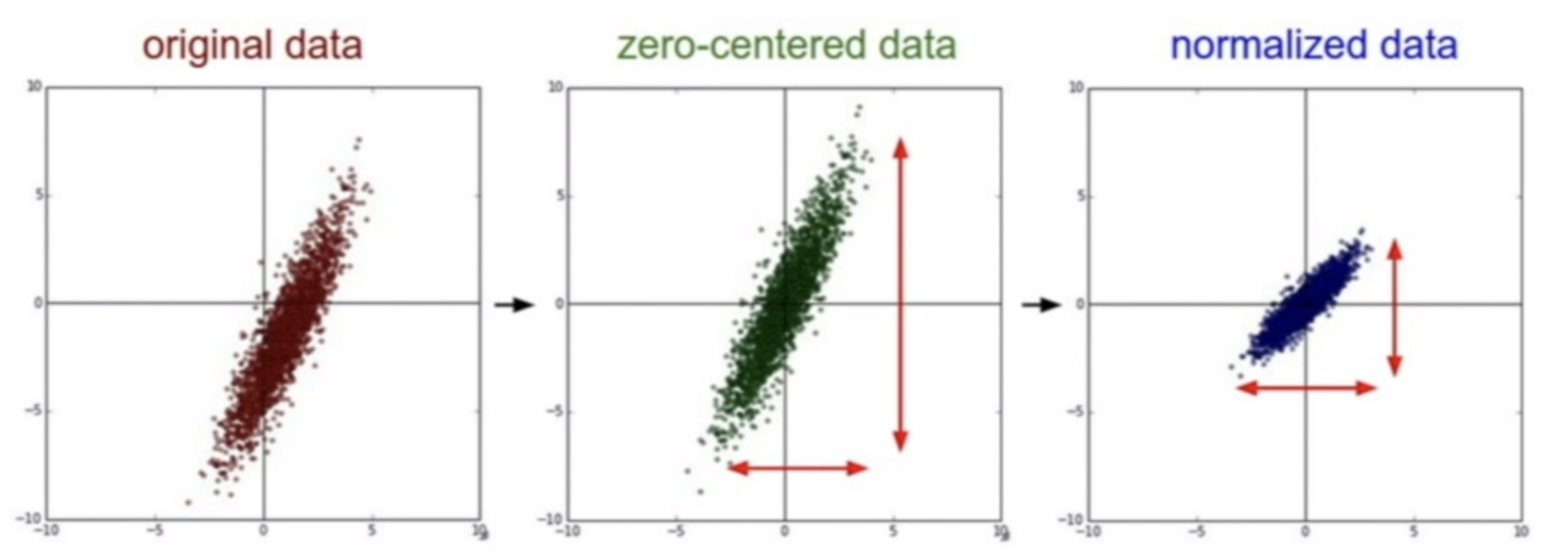
Normalizing inputs
Vanishing / Exploding Gradients

If we use linear activation function \(g(z)=z\), then we can show that \(y = w^{[L]}*w^{[L-1]}*\dots*w^{[1]}\).
Weight Initialization for Deep Networks
Suppose we have a single neuron.
So we’ll have \(z=w_1 x_1 + \dots + w_n x_n\).
The larger \(n\) becomes, the less should the weights \(w_i\) be.
We can set the variance of w to be \(\dfrac{1}{n}\) for \(tanh\) (Xavier initialization) (or \(\dfrac{2}{n}\) for ReLU).
Sometimes also this is used: \(\sqrt{\dfrac{2}{n^{[l-1]}n^{[l]}}}\). \[ w^{[l]} = np.random.randn(w.shape)* np.sqrt(1/n^{[l-1]}) \]
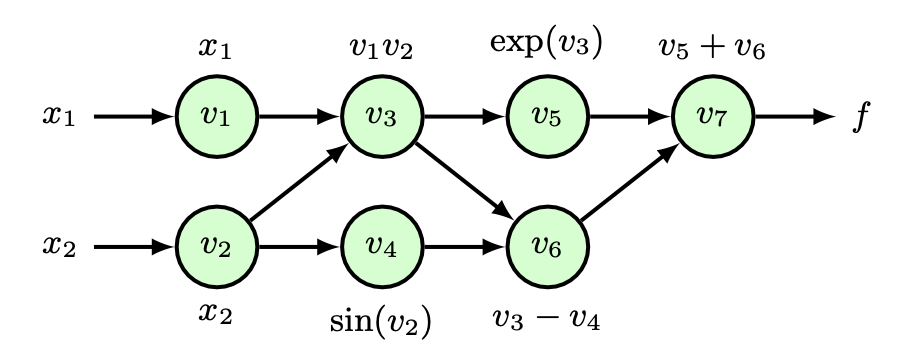
Autodiff
Idea
Automatically generate the code for gradient calculations, based on forward propagation equations.
It augments the forward prop code with additional variables.
Mini-batch Gradient Descent
If we split training sets in smaller sets, we call them mini-batches. 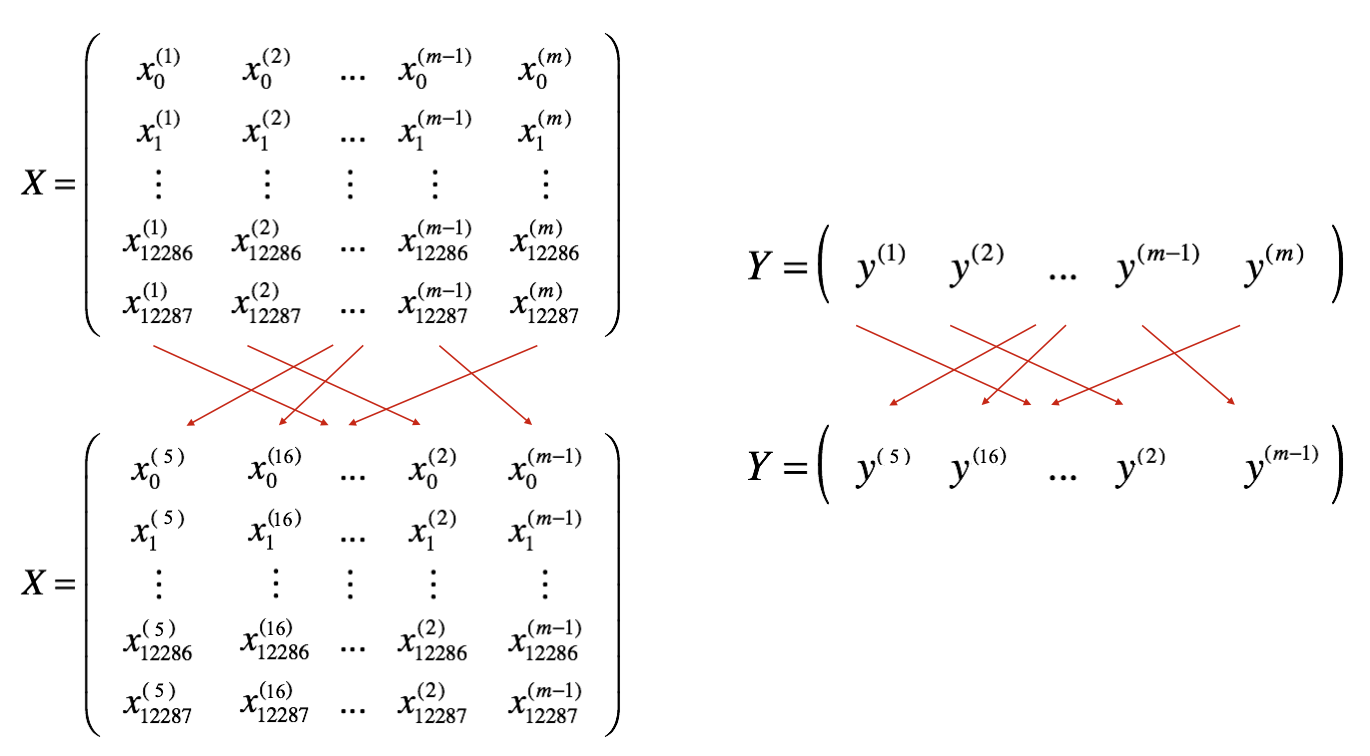
Mini-batch Gradient Descent
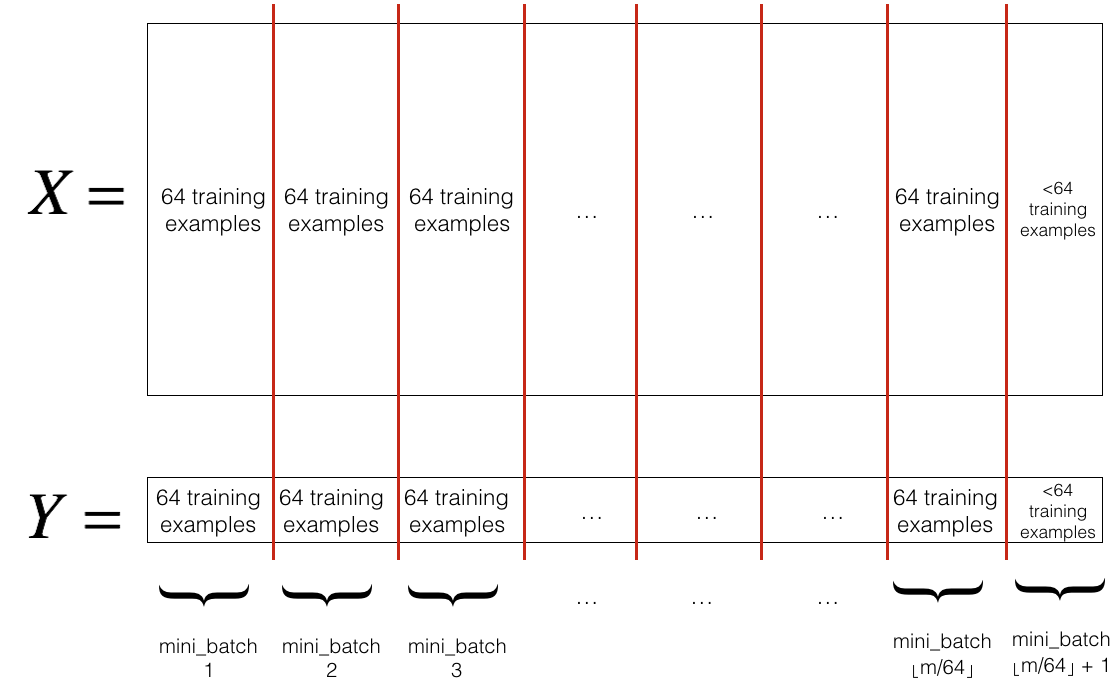
Mini-batch Gradient Descent
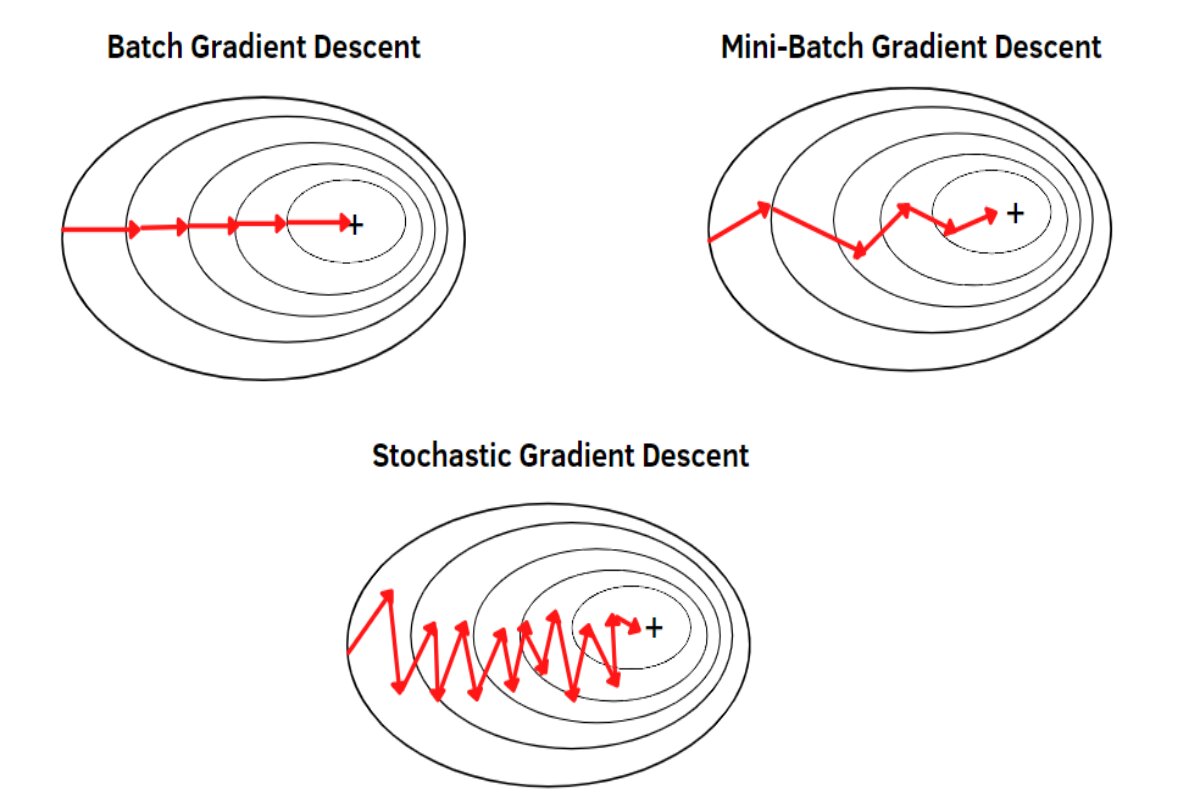
Note
Mini-batch cost will have oscillations, depending on characteristics of mini-batches.
Mini-batch Gradient Descent
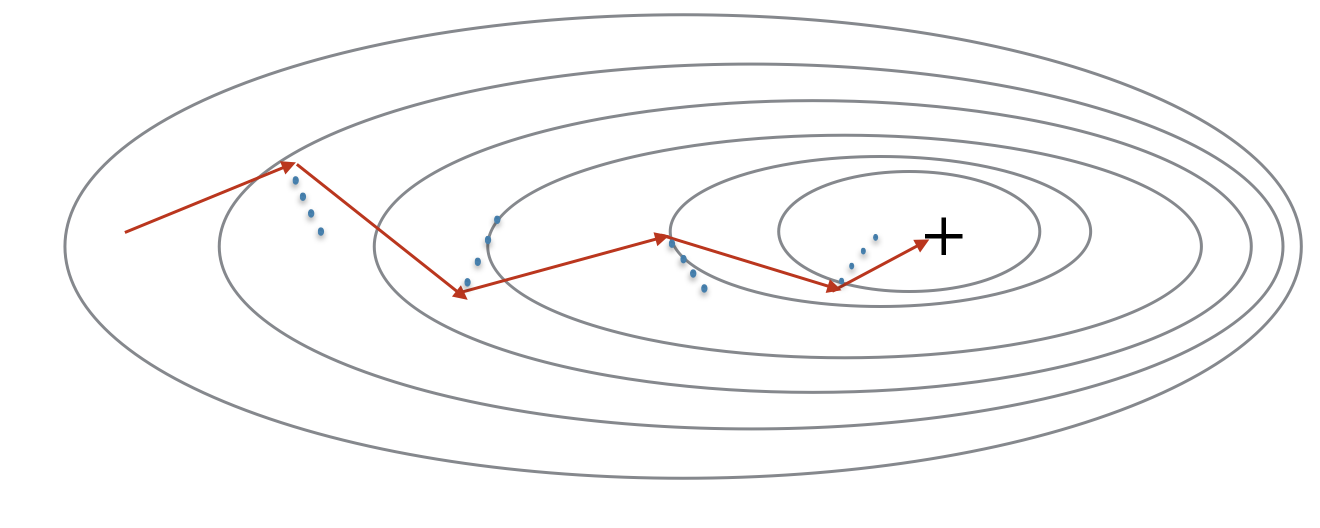
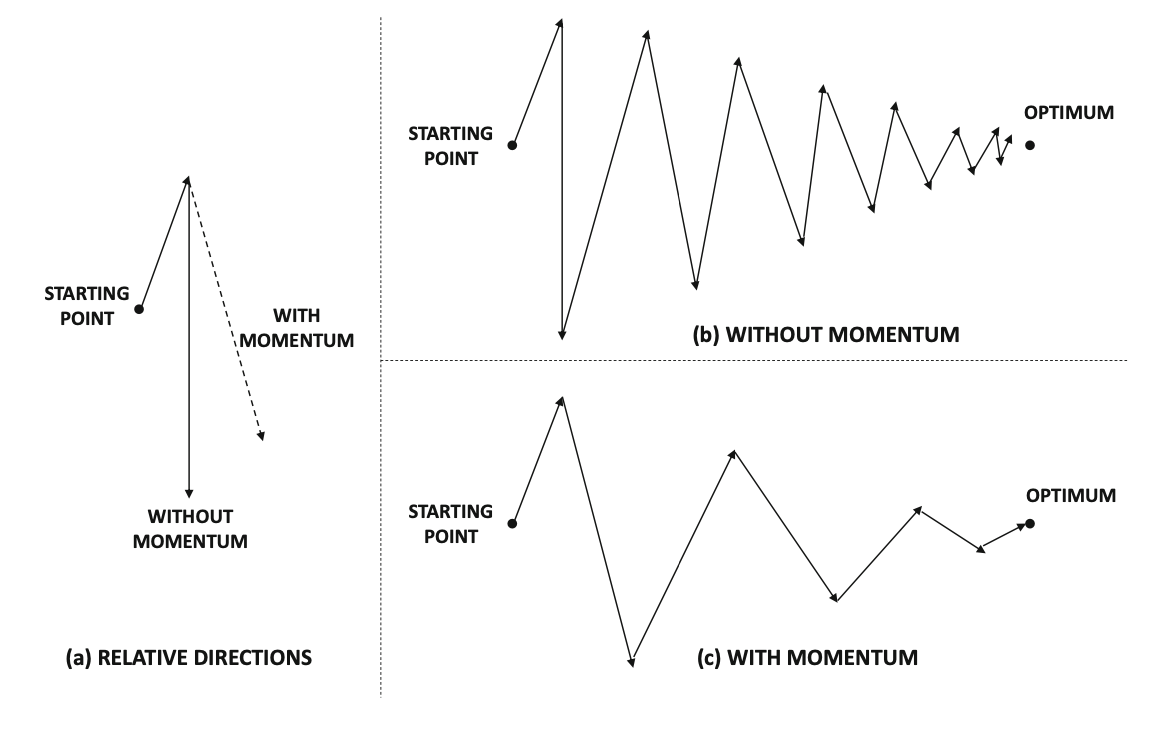
Momentum: intuition
- Because mini-batch gradient descent makes a parameter update after seeing just a subset of examples, the direction of the update has some variance, and so the path taken by mini-batch gradient descent will “oscillate” toward convergence.
- Using momentum can reduce these oscillations.
- Momentum takes into account the past gradients to smooth out the update. The ‘direction’ of the previous gradients is stored in the variable.
- Formally, this will be the exponentially weighted average of the gradient on previous steps. You can also think of as the “velocity” of a ball rolling downhill.
Exponentially Weighted Averages
Speed
Faster than GD.
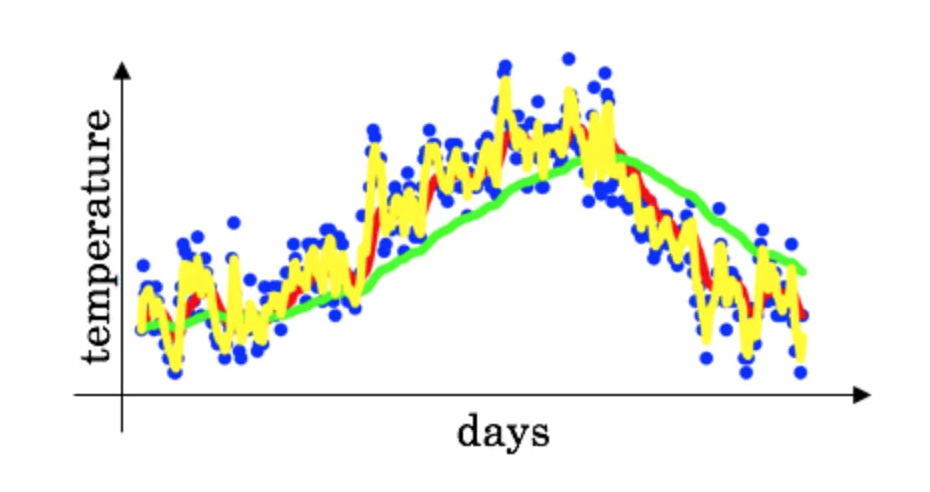
Exponentially weighted (moving) averages for yearly temperatures: \[ V_t = \beta*V_{t-1} + (1-\beta)*\theta_t \] where \(v_0=0\), \(\theta_i\) is temperature on day \(i\).
Exponentially Weighted Averages
Bias Correction in Exponentially Weighted Averages
The problem is that the curves starts really low.
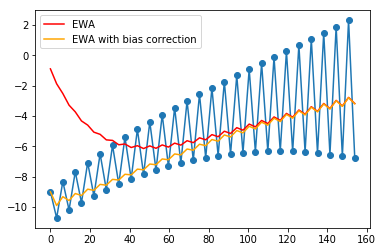
Suggestion
Divide \(v_t\) by \(1-\beta^t\).
Gradient Descent with Momentum
Basic idea
To compute exponentially weighted average of gradients and use that in GD update step. Helps the Gradient Descent process in navigating flat regions and local optima.
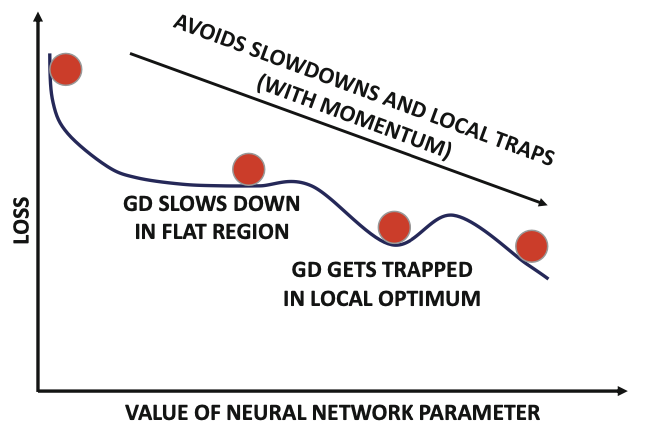
Gradient Descent with Momentum
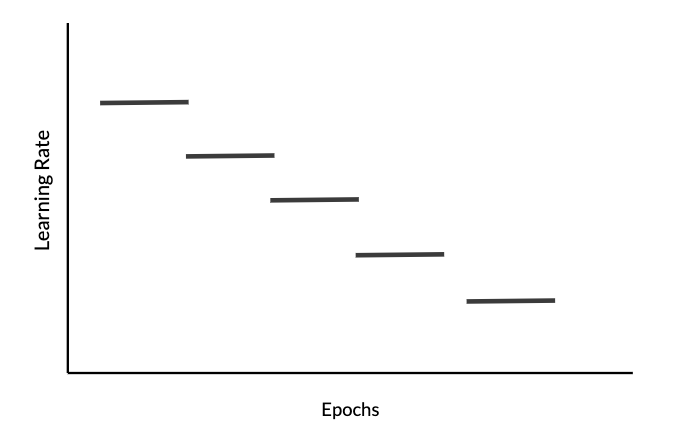
Learning Rate Decay
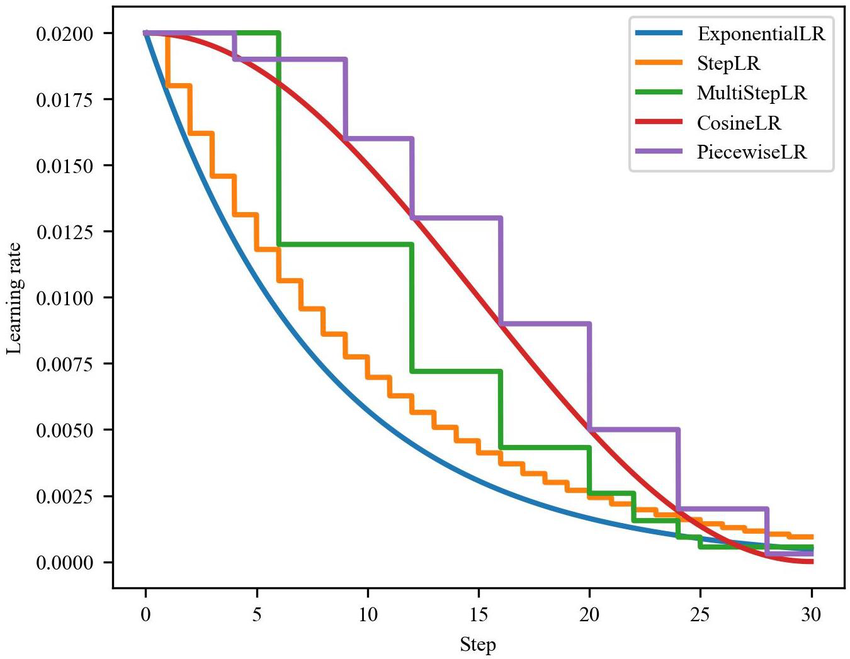
Learning Rate Decay
Manual decay: works if we train on a small number of models.
Fixed interval scheduling