Current frontiers
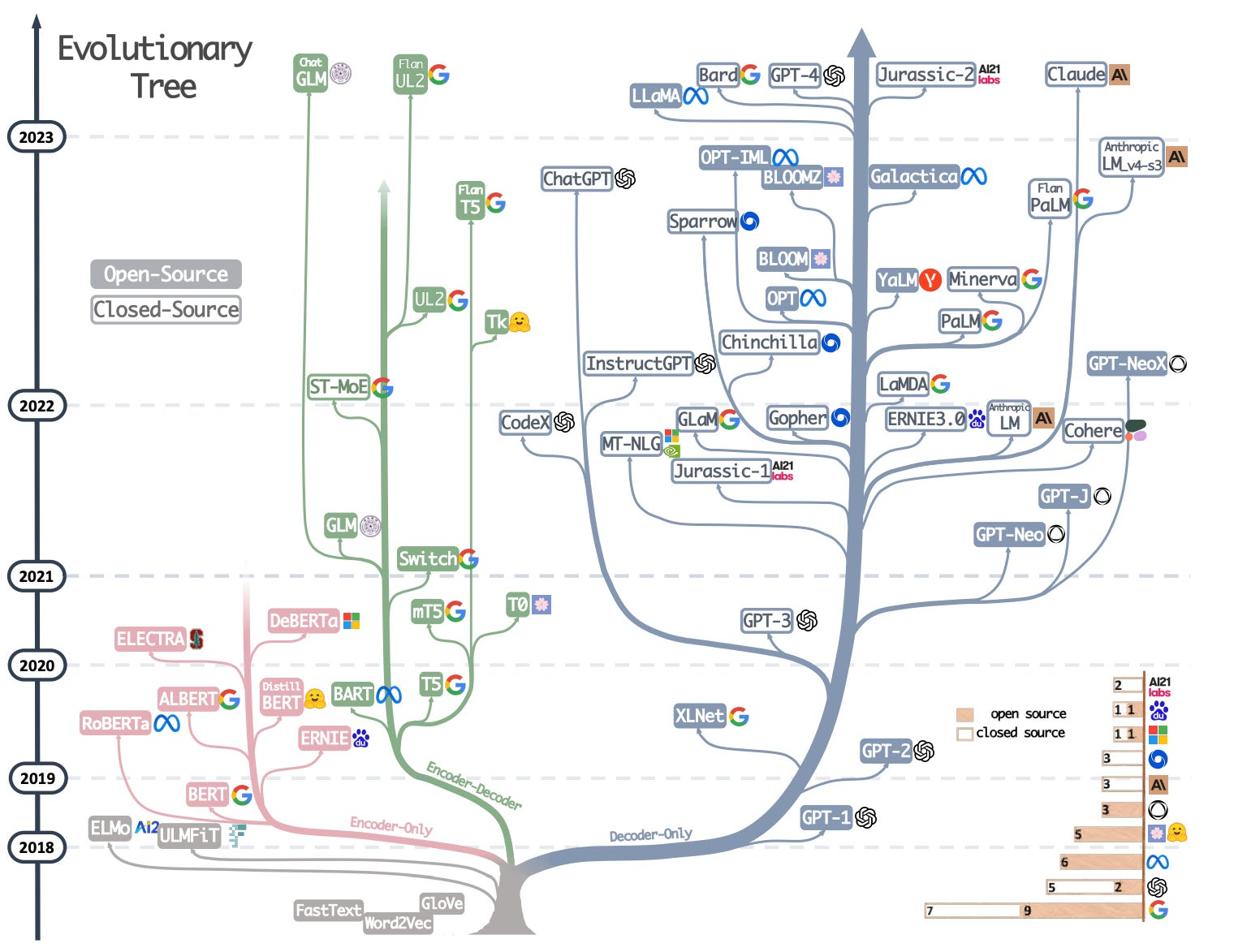
LLM tree
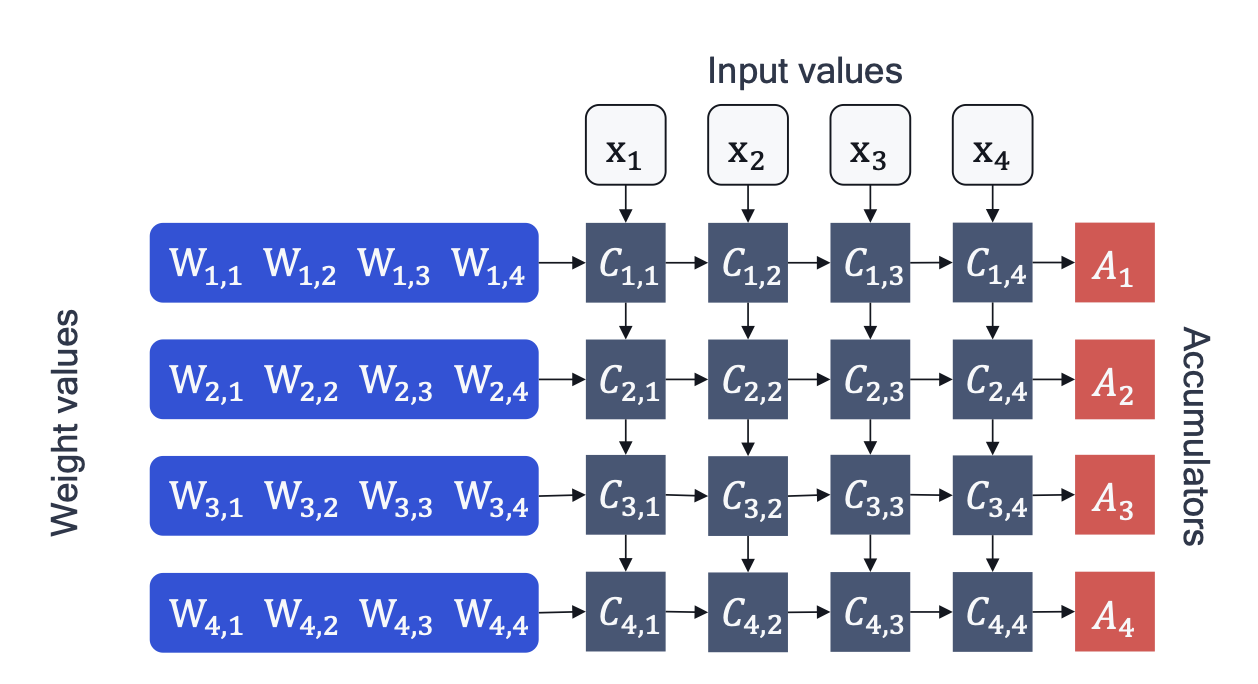
1-bit LLMs
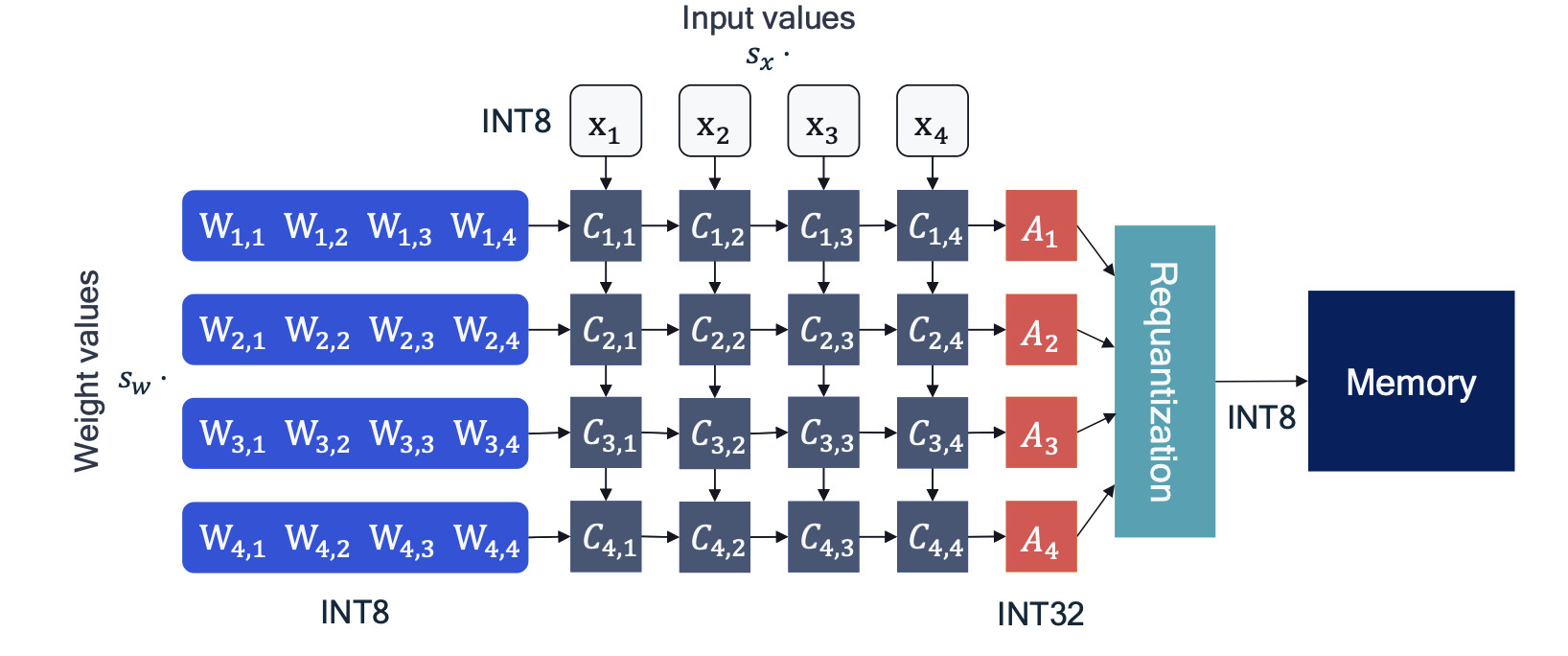
1-bit LLMs
1-bit LLMs
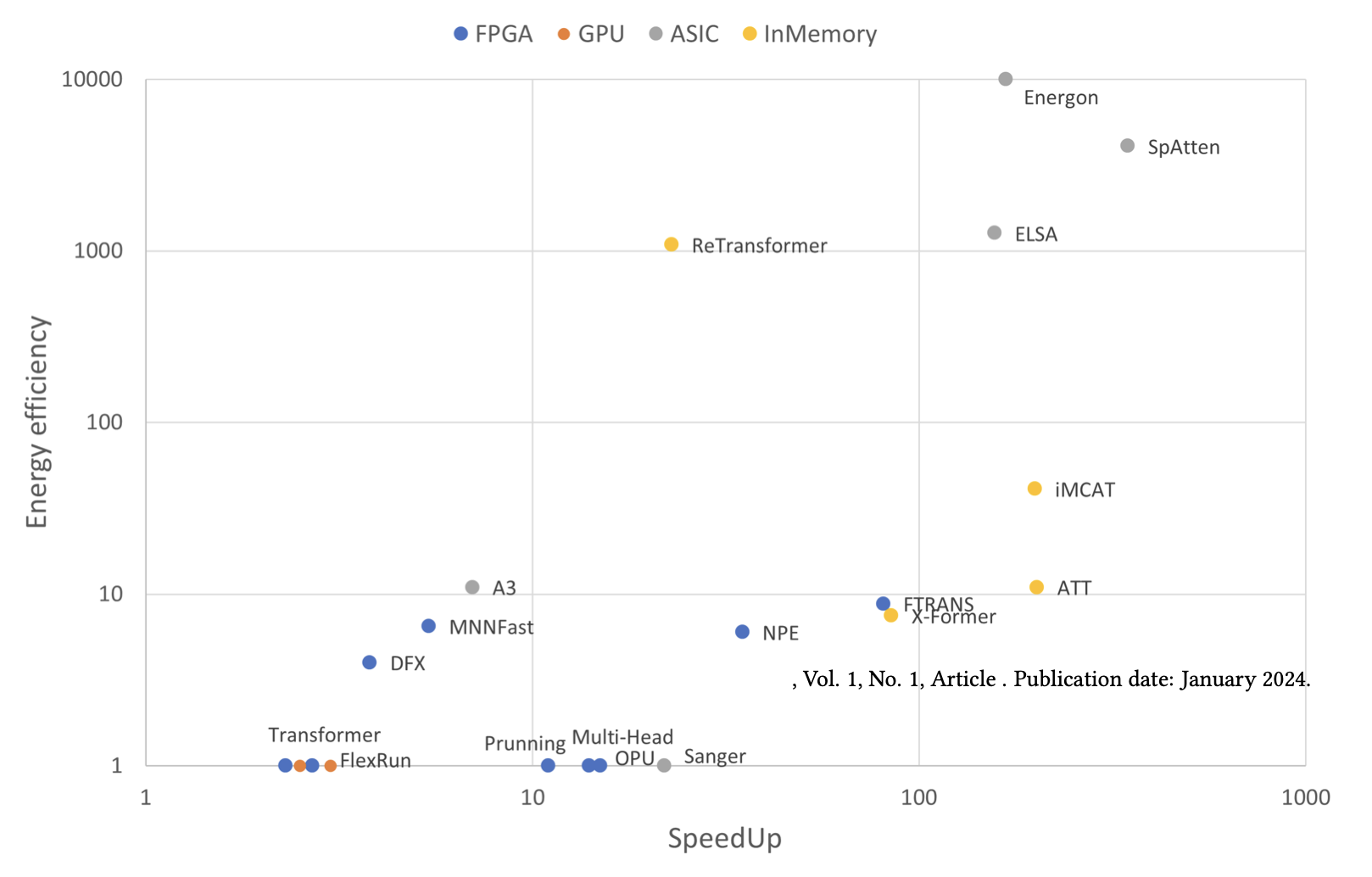
1-bit LLMs

Groq LPU die
1-bit LLMs
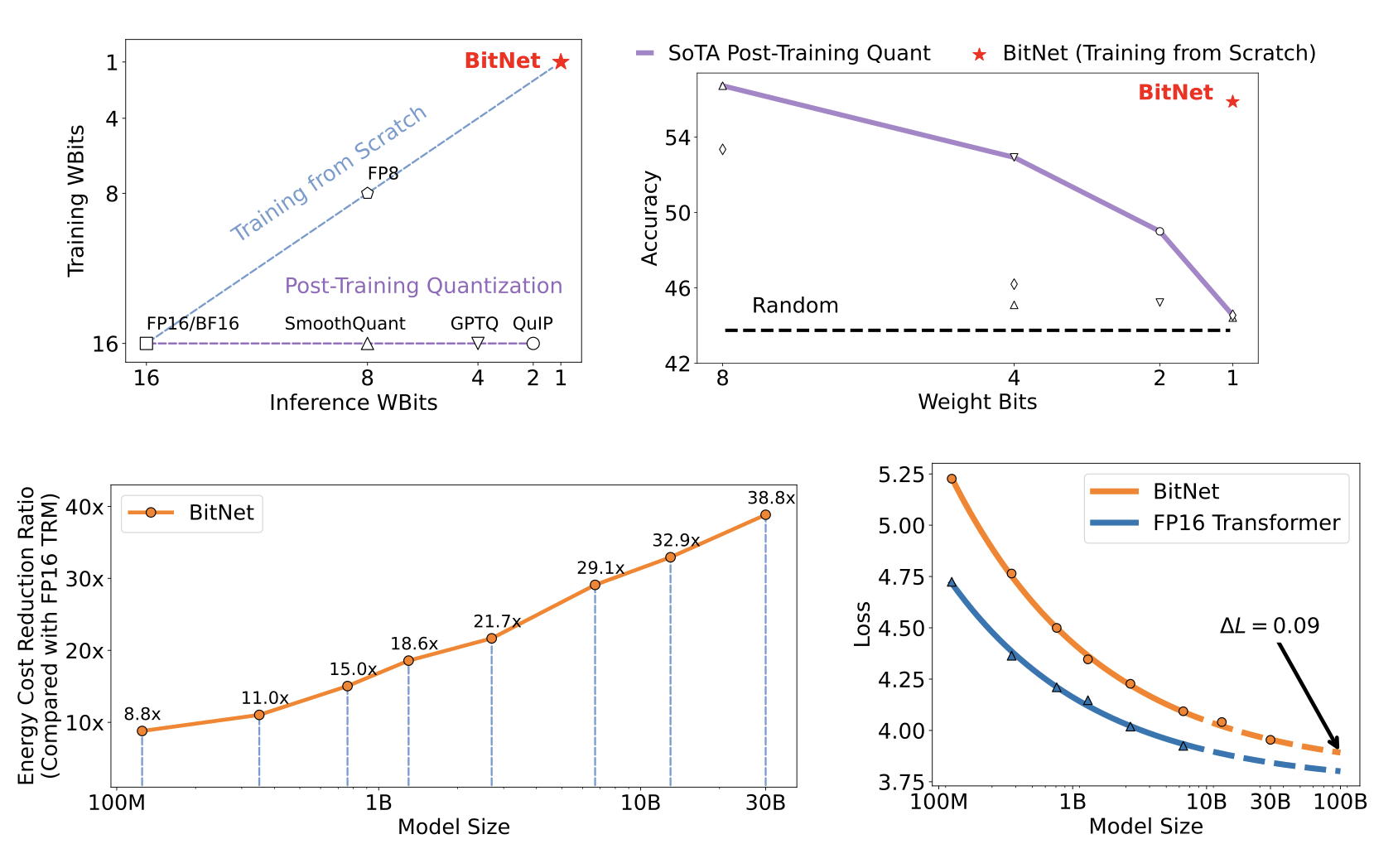
BitNet trains 1-bit Transformers from scratch, obtaining competitive results in an energy-efficient way.
1-bit LLMs
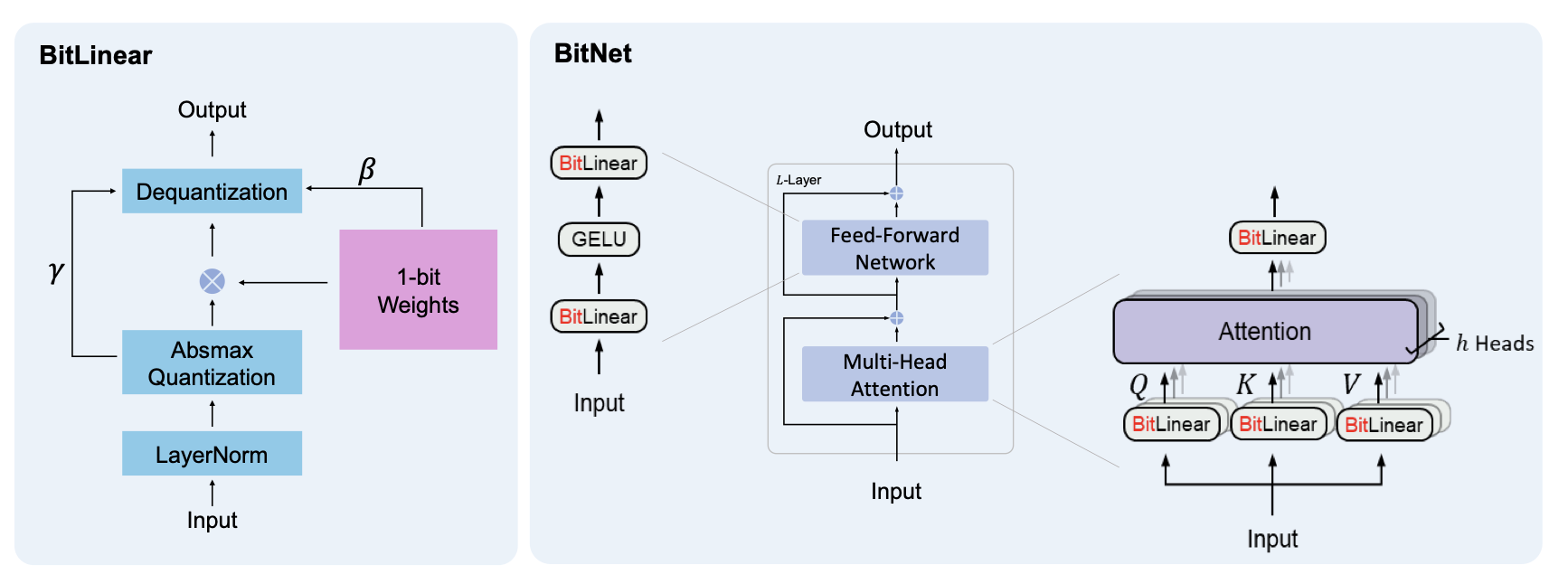
Left: The computation flow of BitLinear. Right: The architecture of BitNet, consisting of the stacks of attentions and FFNs, where matrix multiplication is implemented as BitLinear.
1-bit LLMs: Parallelism

1-bit LLMs: Parallelism
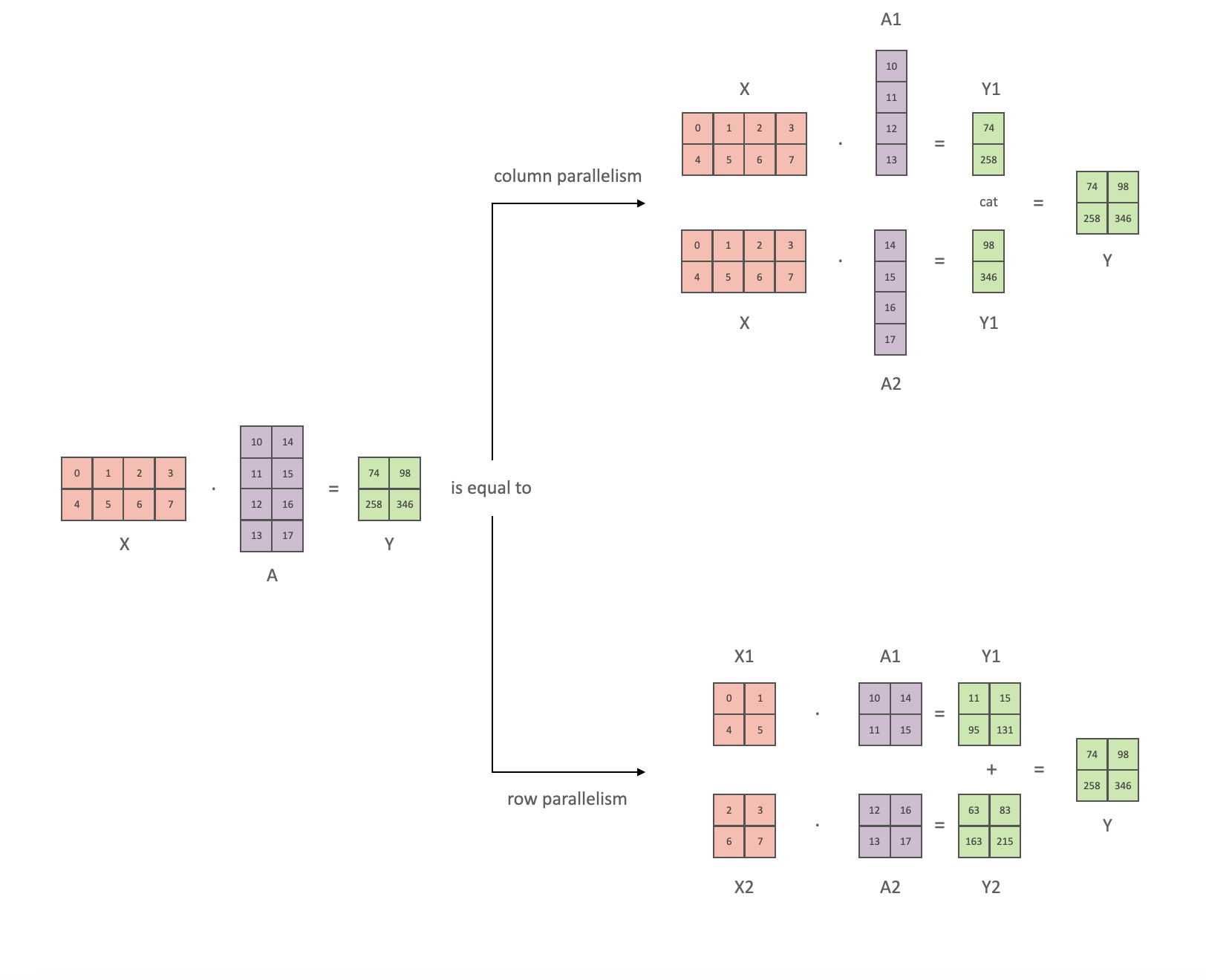
Tensor parallelism
1-bit LLMs
1-bit LLMs
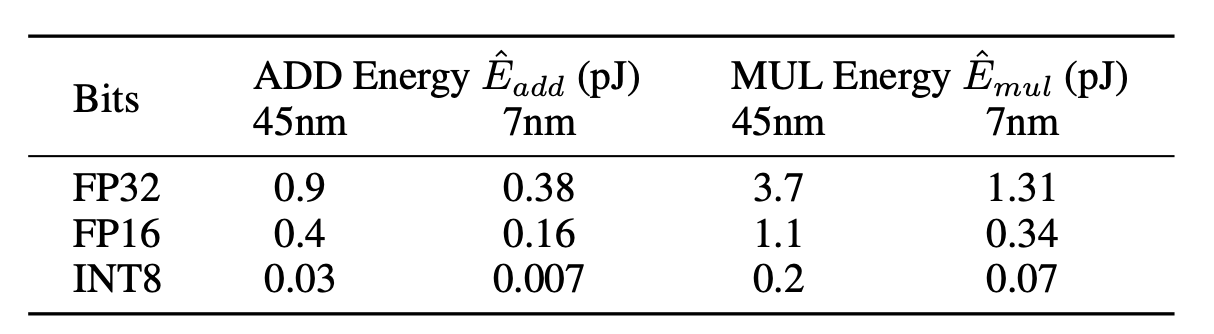
1-bit LLMs
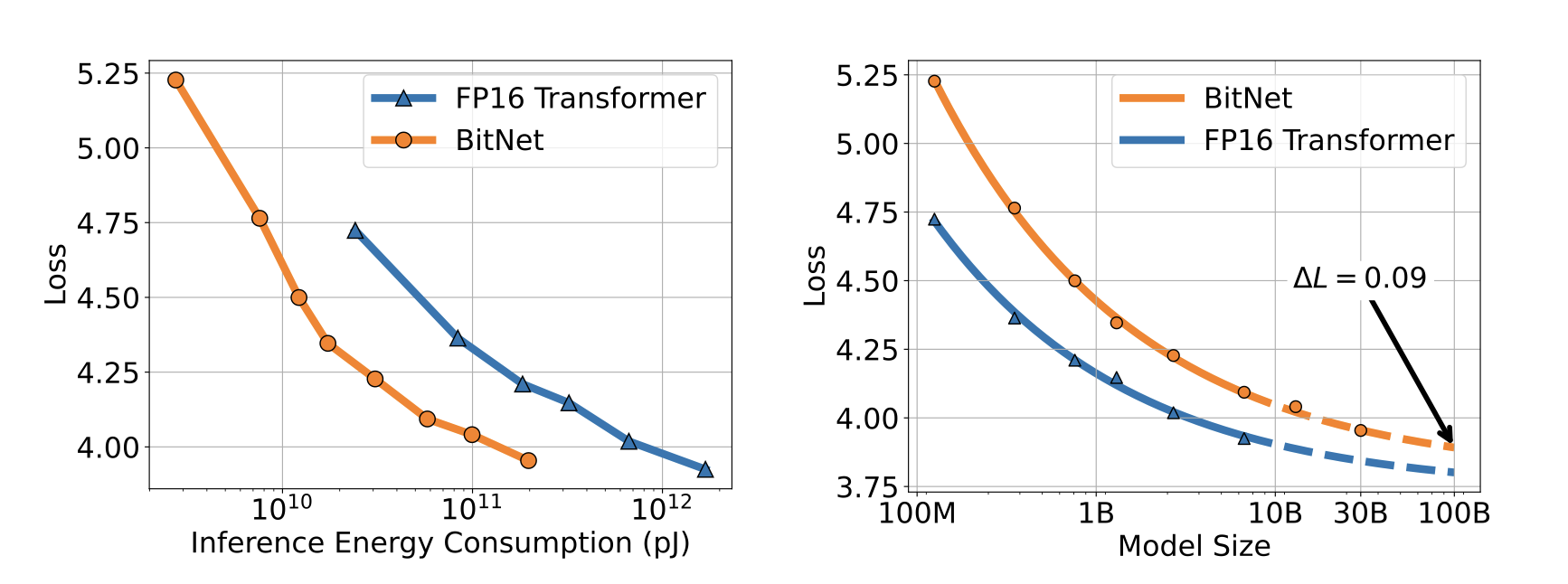
Scaling curves of BitNet and FP16 Transformers.
1-bit LLMs
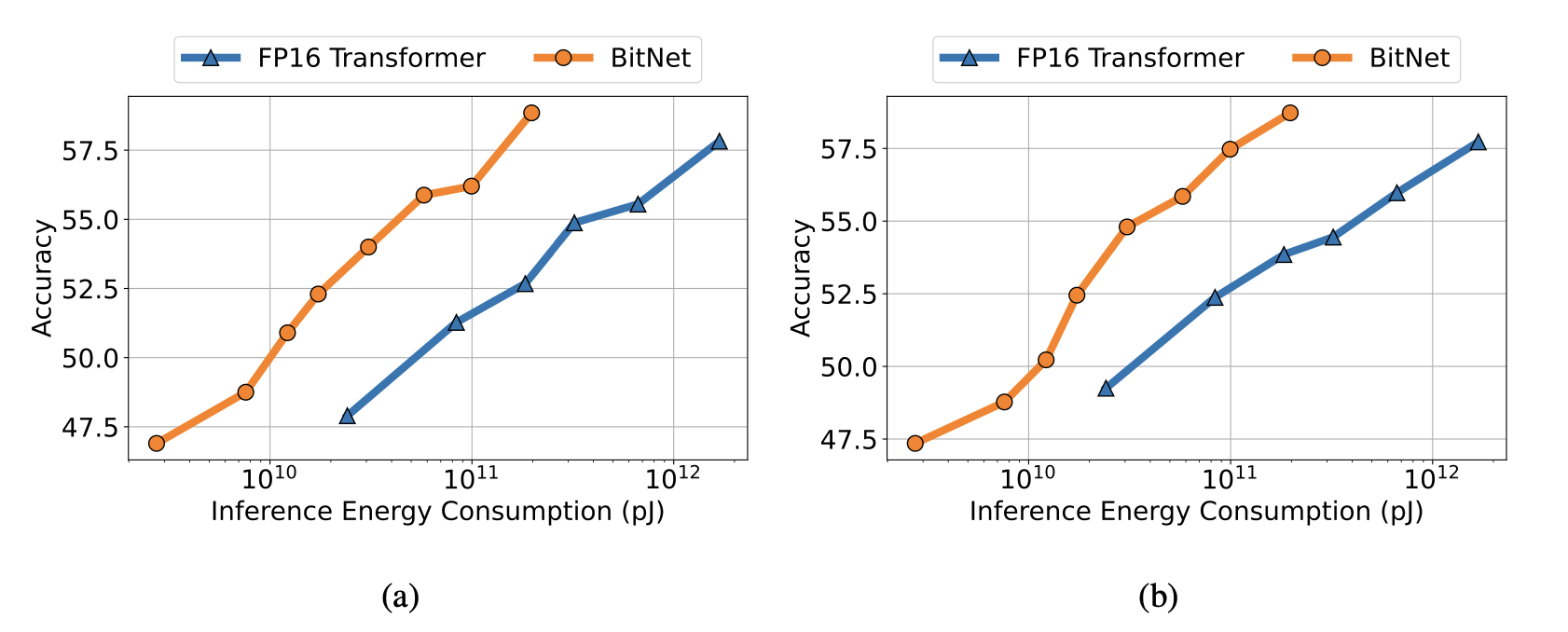
Zero-shot (Left) and few-shot (Right) performance of BitNet and FP16 Transformer against the inference cost.
1-bit LLMs
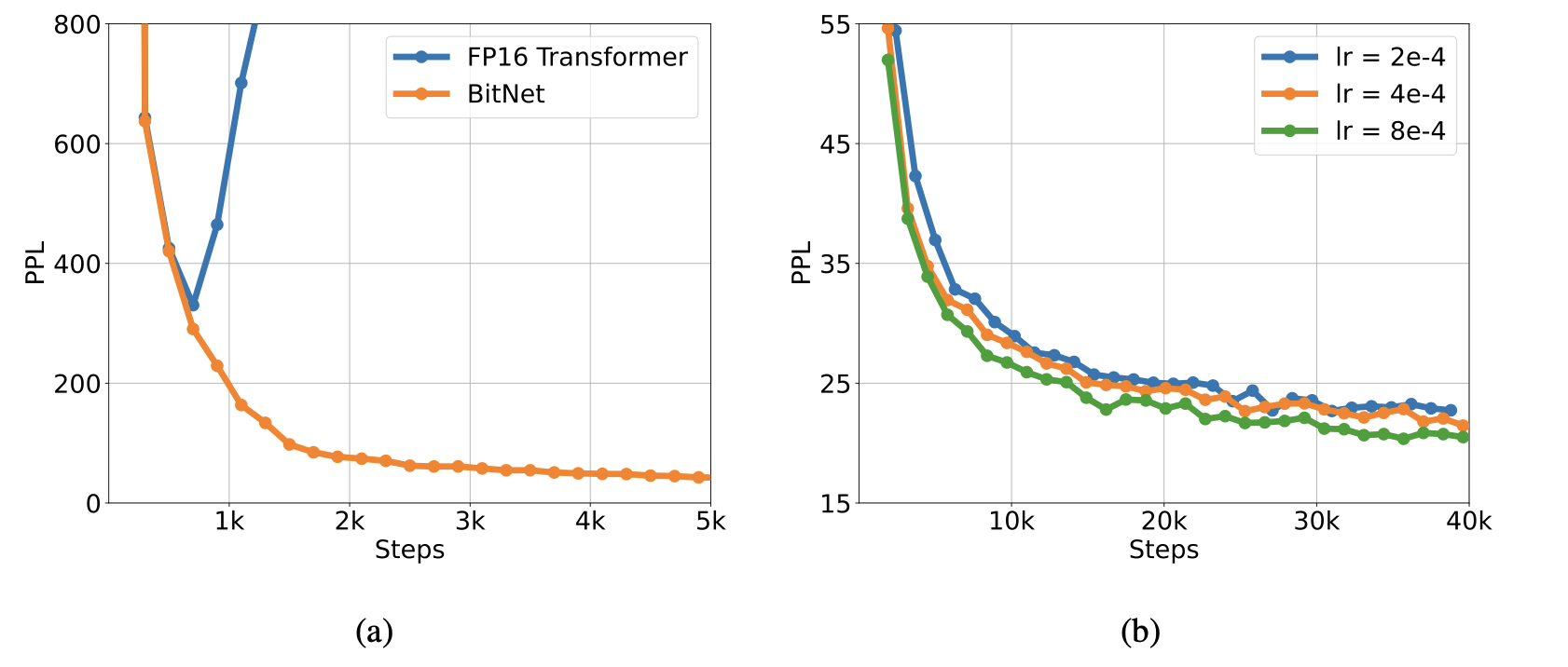
BitNet is more stable than FP16 Transformer with a same learning rate (Left). The training stability enables BitNet a larger learning rate, resulting in better convergence (Right).
1-bit LLMs
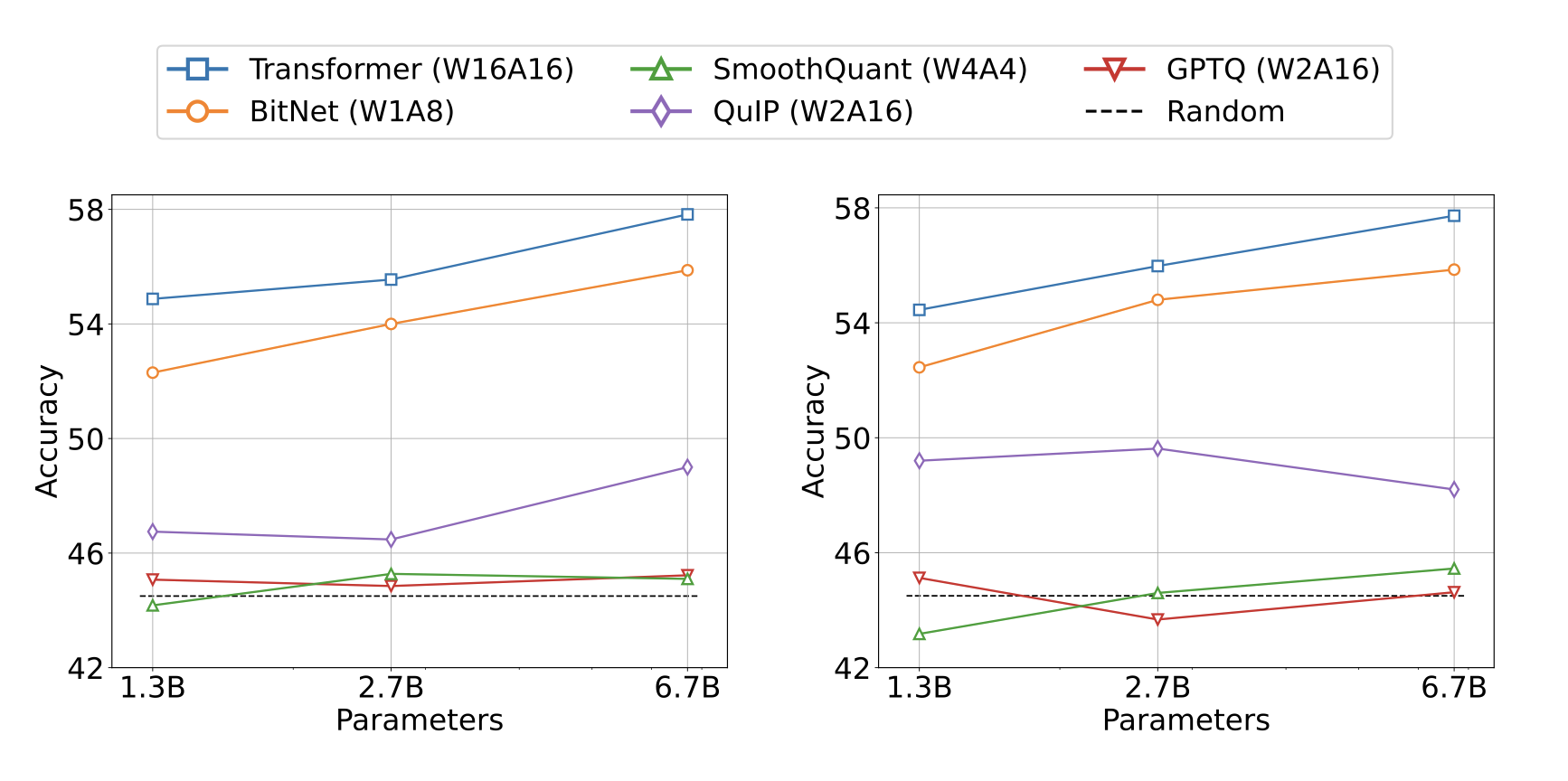
Zero-shot (Left) and few-shot (Right) results for BitNet and the post-training quantization baselines on downstream tasks.
BitNet b1.58
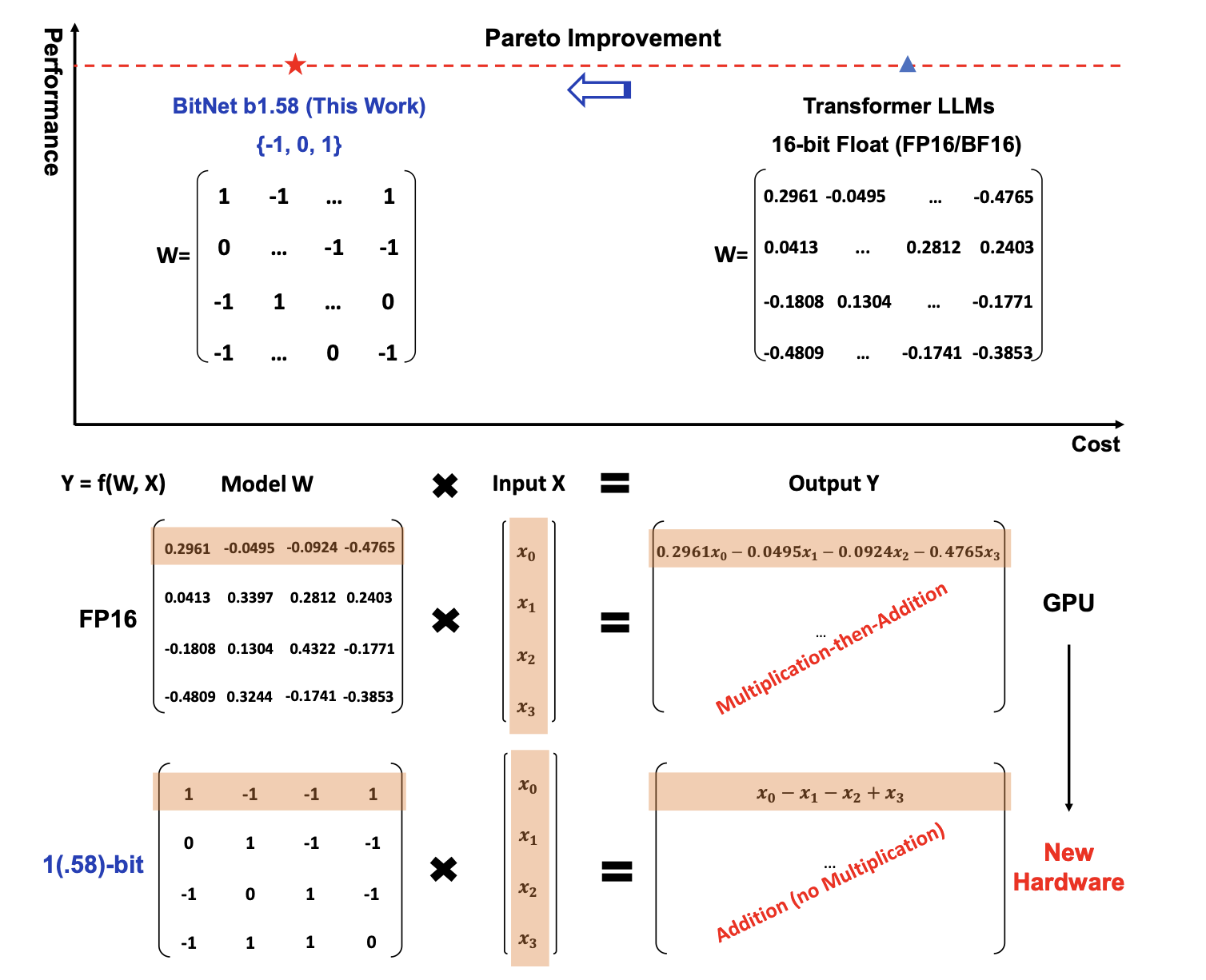
BitNet b1.58
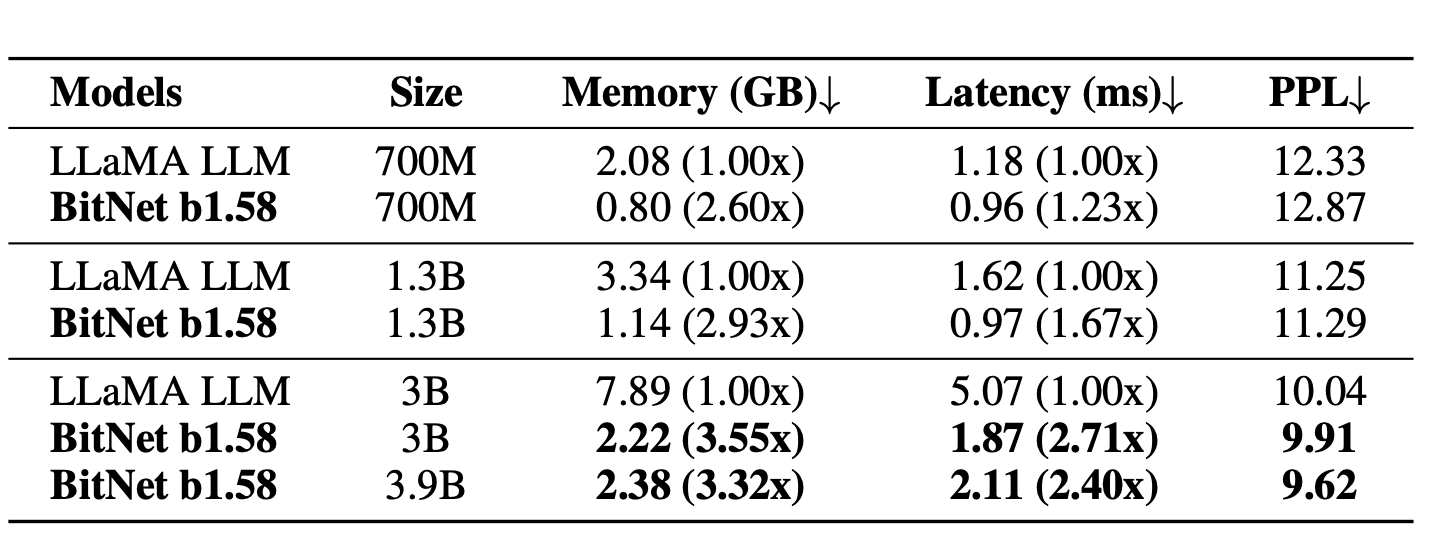
Perplexity as well as the cost of BitNet b1.58 and LLaMA LLM.
BitNet b1.58
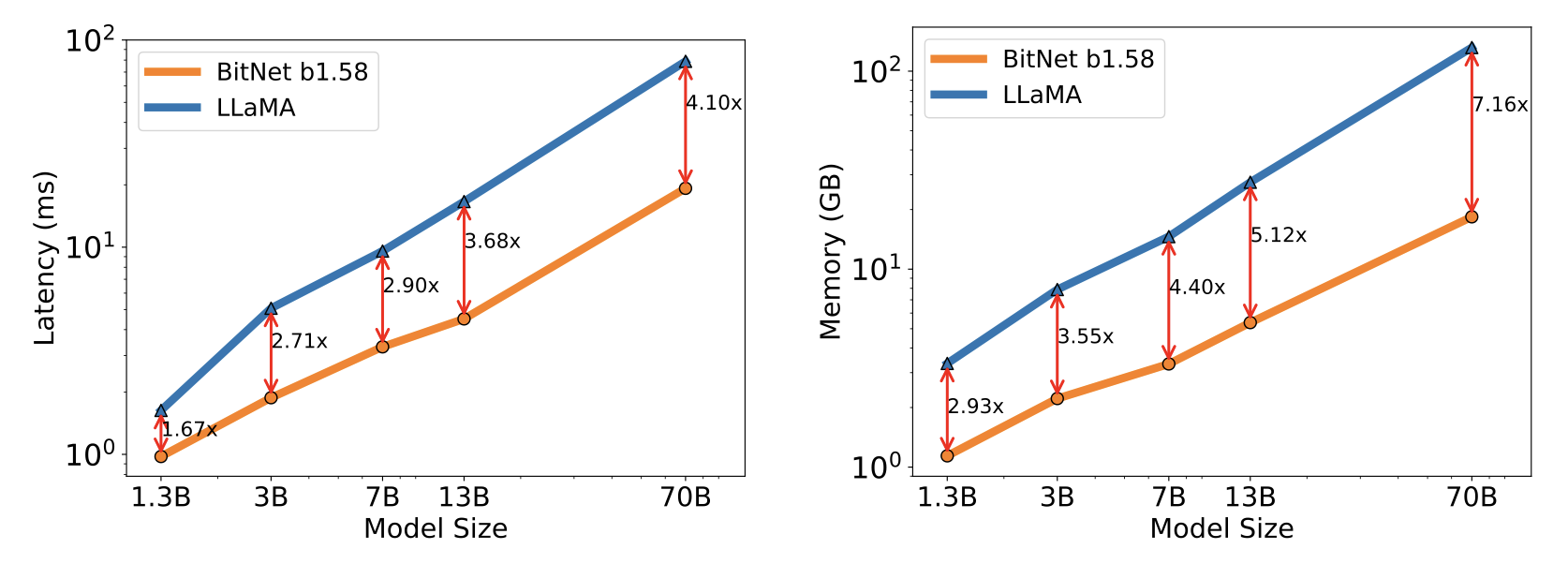
Decoding latency (Left) and memory consumption (Right) of BitNet b1.58 varying the model size.
BitNet b1.58
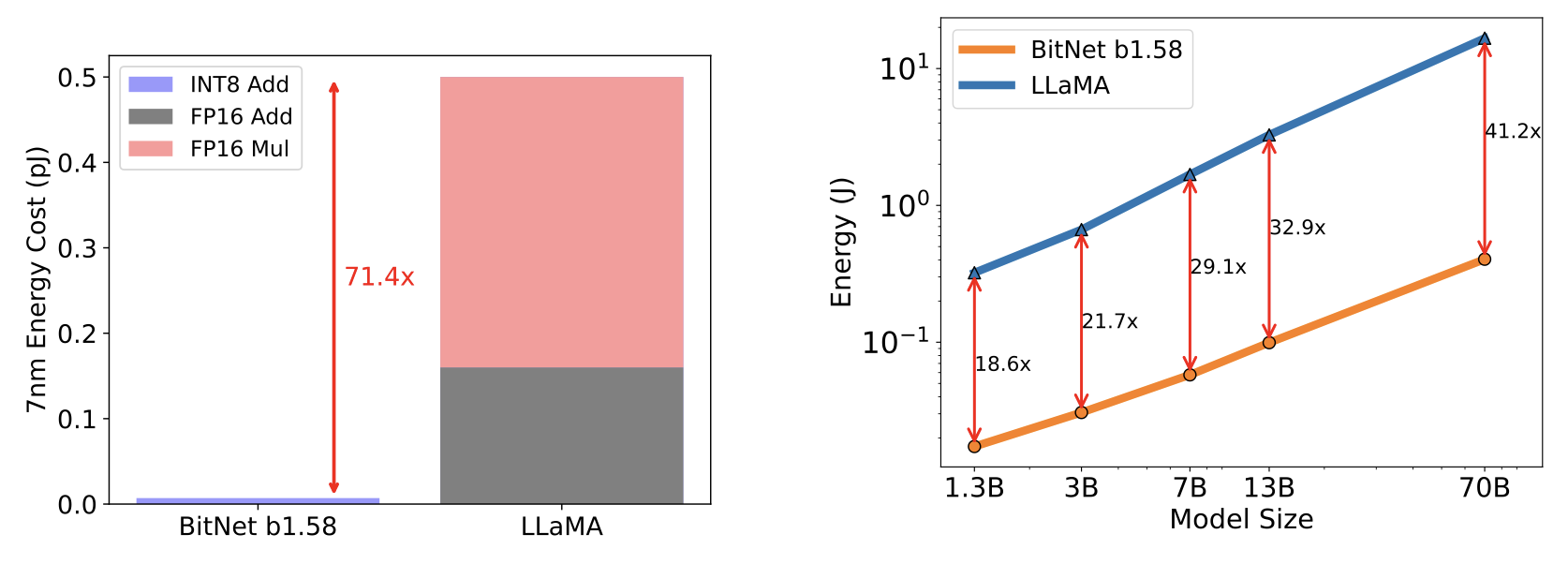
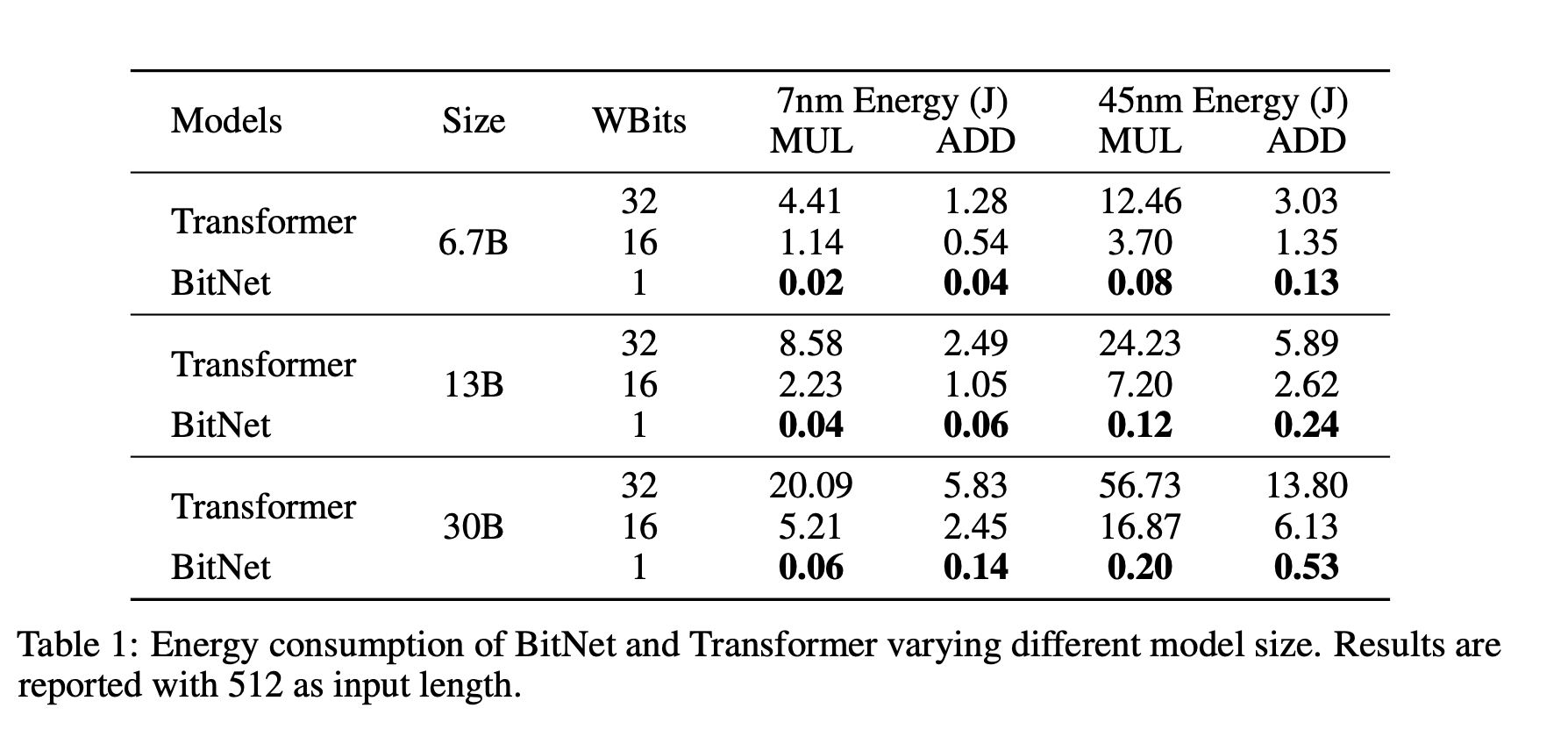
Energy consumption of BitNet b1.58 compared to LLaMA LLM at 7nm process nodes. On the left is the components of arithmetic operations energy. On the right is the end-to-end energy cost across different model sizes.
Dynamic Neural Networks

The three types of DNNs dynamically adjust computation timewise, widthwise and depthwise, respectively.
Neuroevolution
Graph Neural Networks

Graph Neural Networks
Graph Neural Networks

Region Adjacency Graph.
Graph Neural Networks
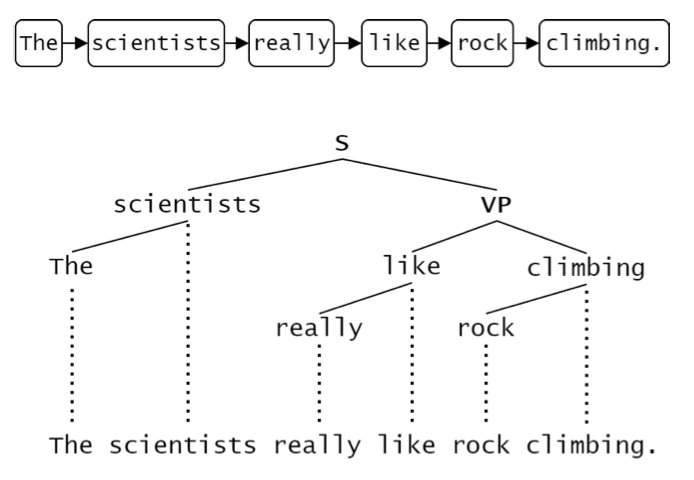
Reed-Kellogg sentence diagram.
Graph Neural Networks
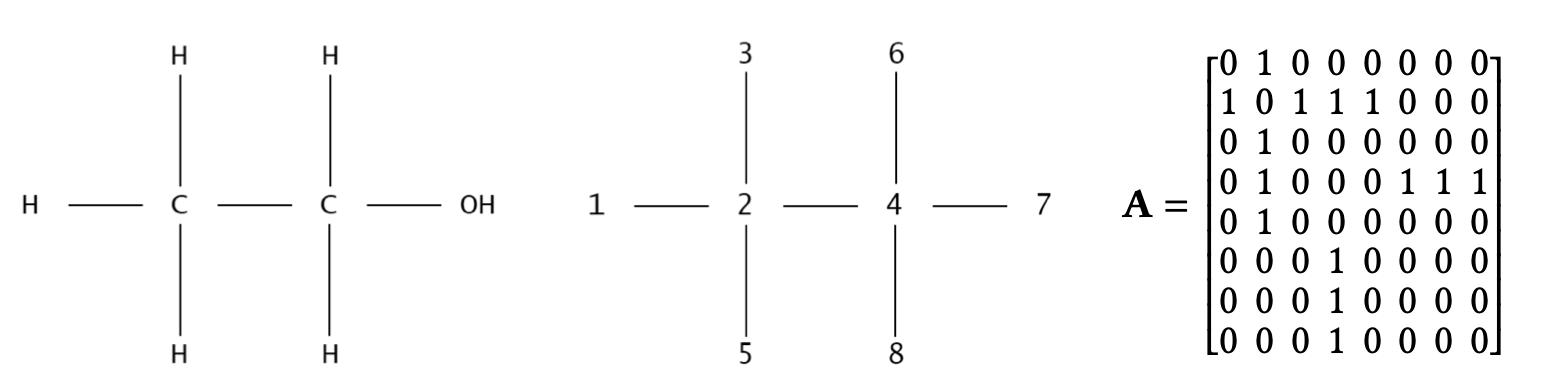
Diagram of an alcohol molecule (left), graph representation with indices (middle), and adjacency matrix (right).
Graph Neural Networks
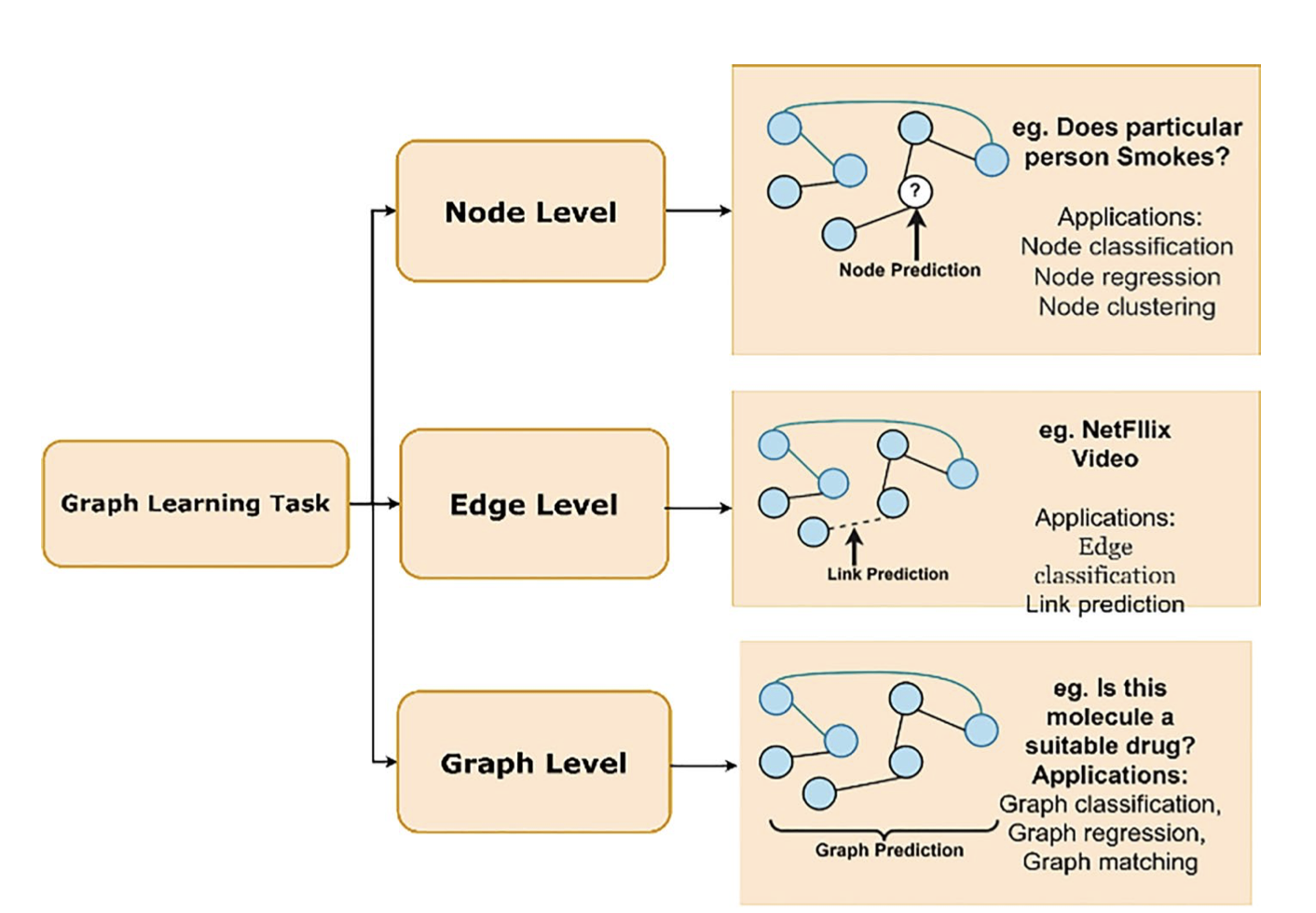
Graph Learning Tasks.
Recurrent Graph Neural Networks
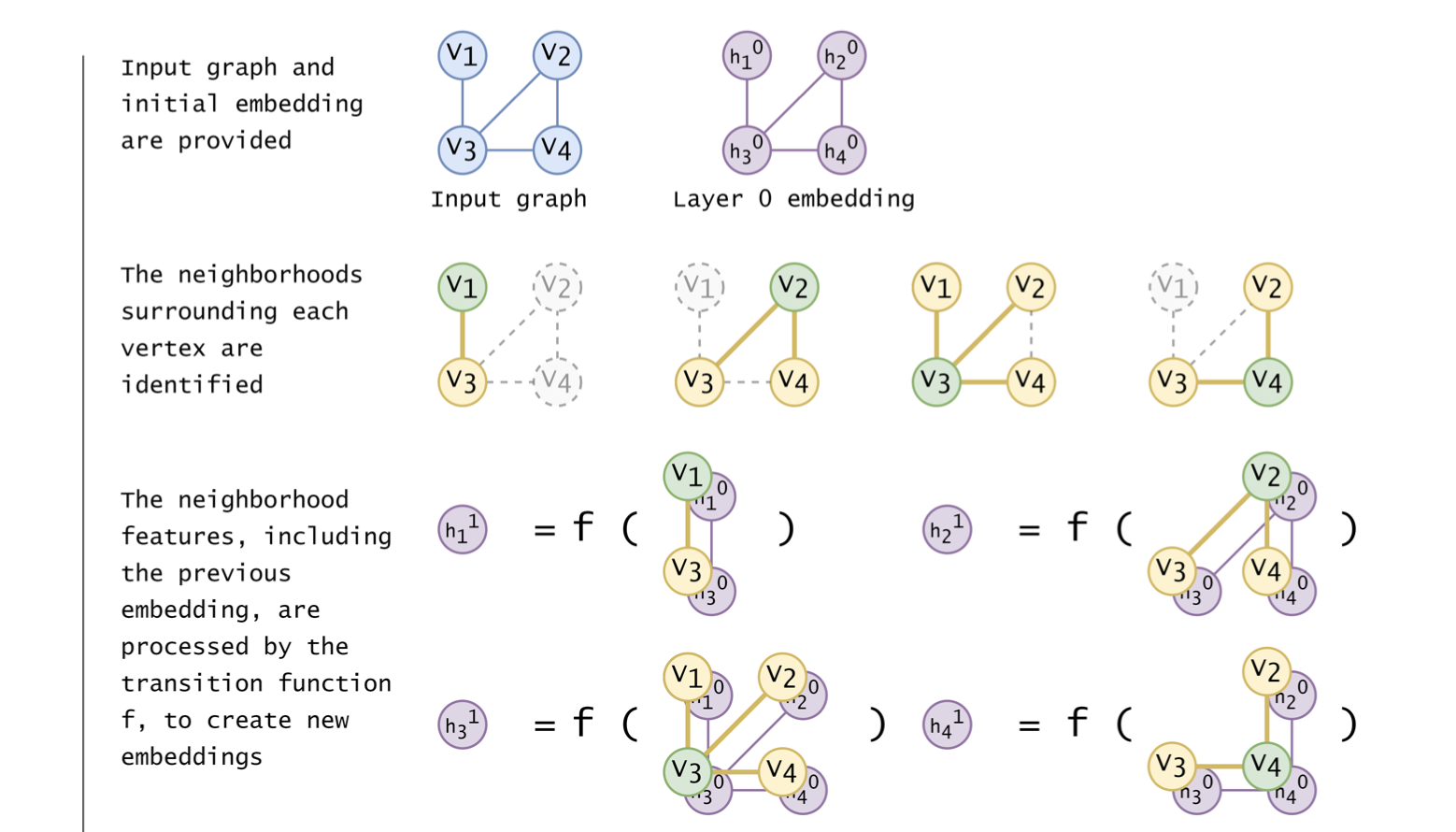
An RGNN forward pass for graph \(G(V,E)\) with \(|V|=4, |E|=4\).
Recurrent Graph Neural Networks
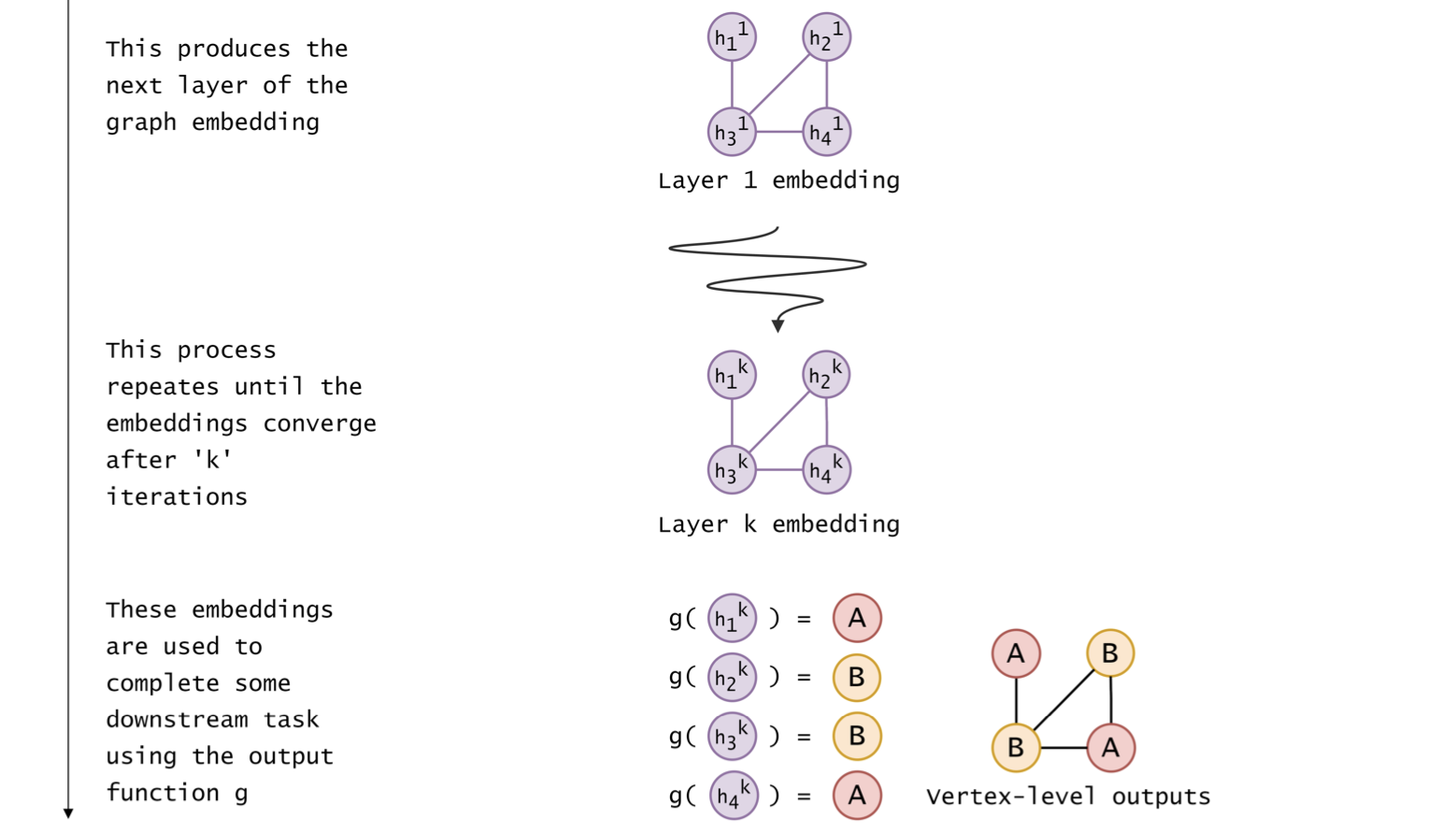
Graph \(G\) goes through \(k\) layers of processing.
Recurrent Graph Neural Networks
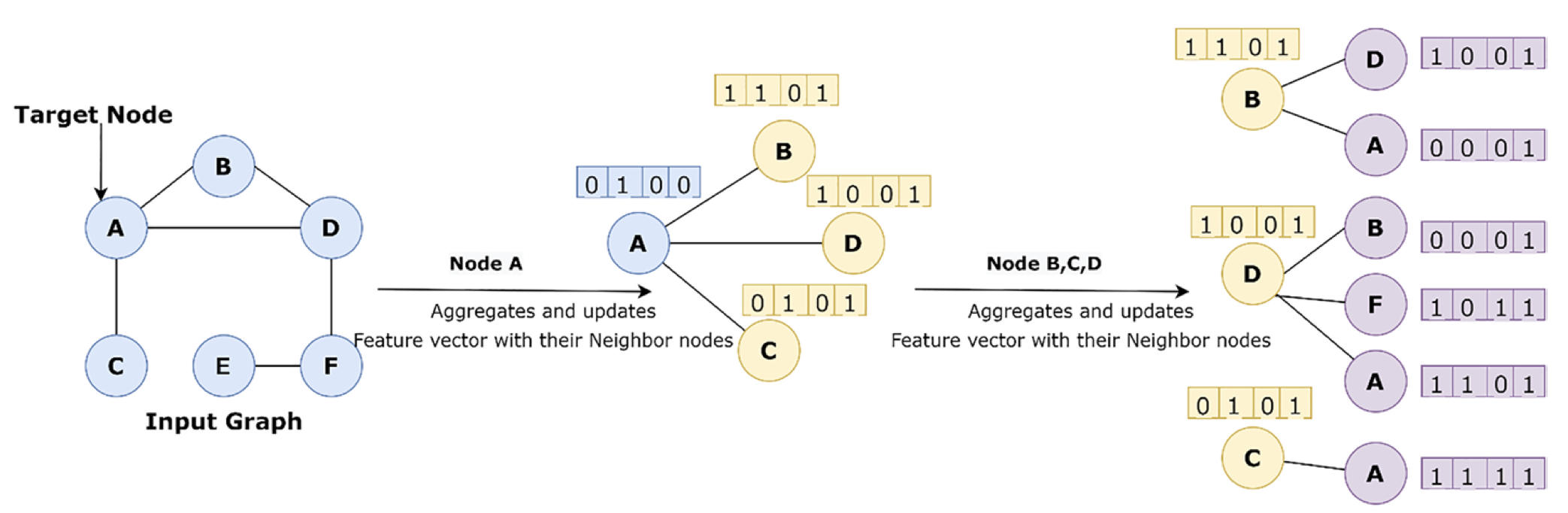
Single node aggregates messages from adjacent nodes.
Convolutional Graph Neural Networks
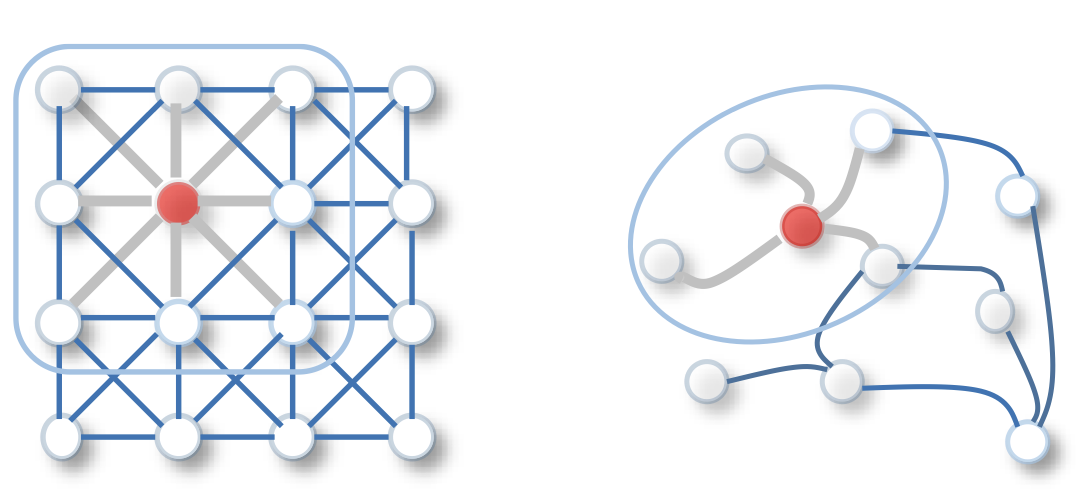
2D Convolution vs. Graph Convolution.
Convolutional Graph Neural Networks

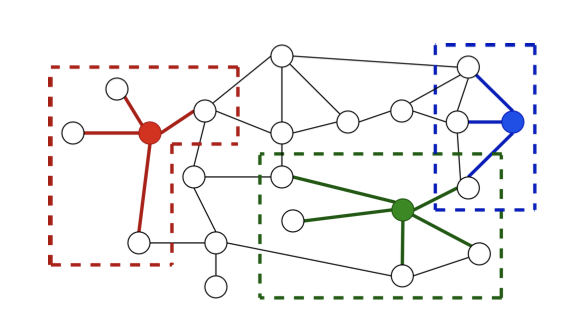
Graph Convolutional Network
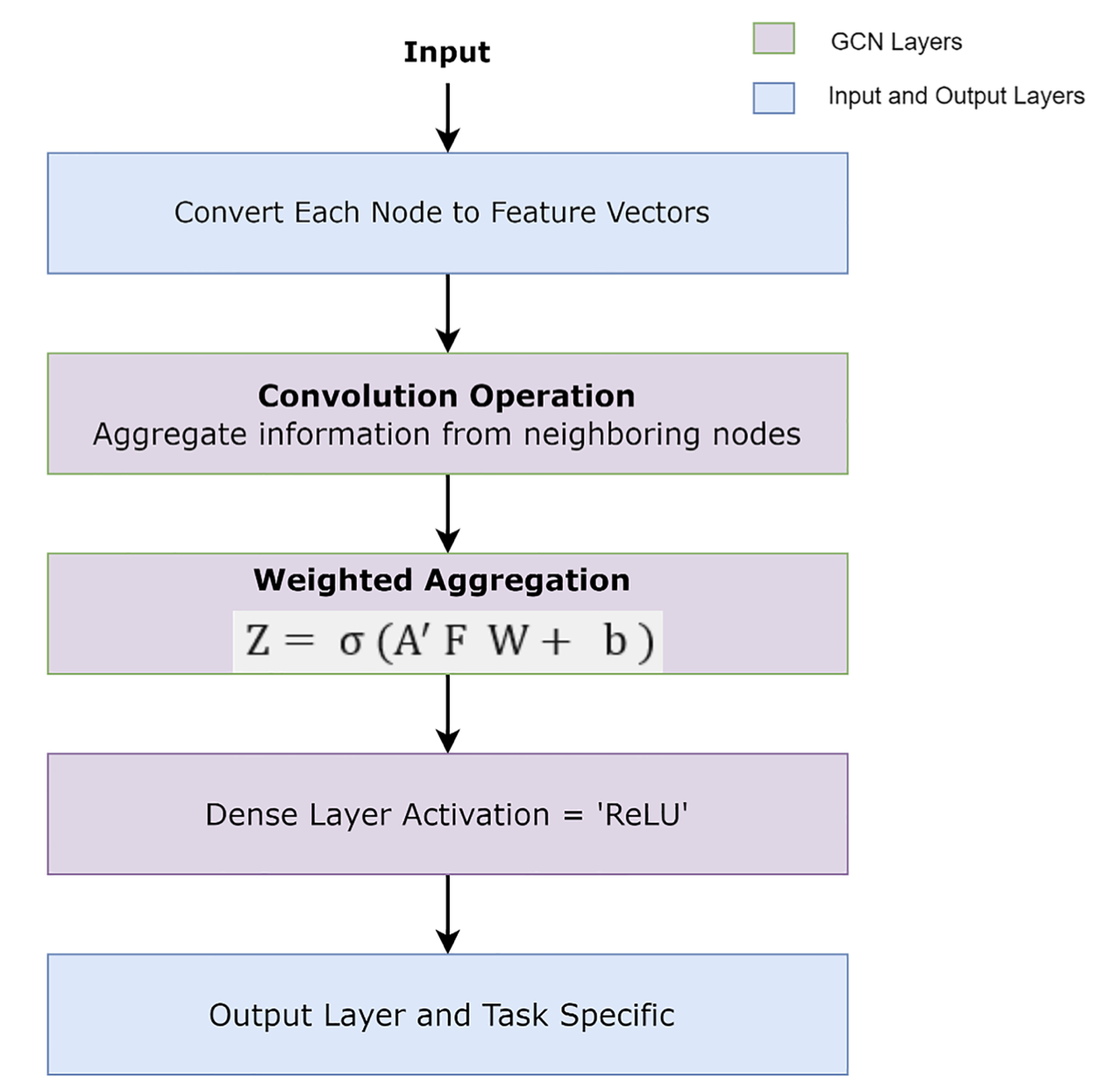
Graph Convolutional Network
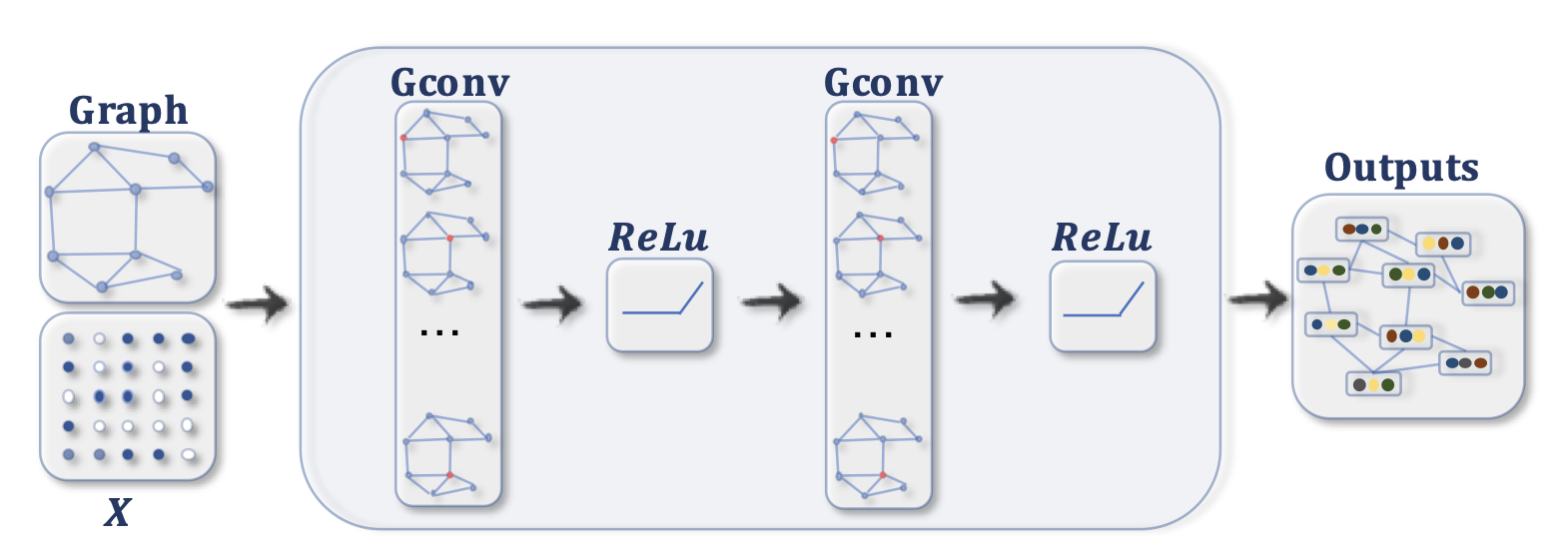
A ConvGNN with multiple graph convolutional layers. A graph convolutional layer encapsulates each node’s hidden representation by aggregating feature information from its neighbors. After feature aggregation, a non-linear transformation is applied to the resulted outputs. By stacking multiple layers, the final hidden representation of each node receives messages from a further neighborhood.
Graph Convolutional Network

A ConvGNN with pooling and readout layers for graph classification. A graph convolutional layer is followed by a pooling layer to coarsen a graph into sub-graphs so that node representations on coarsened graphs represent higher graph-level representations. A readout layer summarizes the final graph representation by taking the sum/mean of hidden representations of sub-graphs.
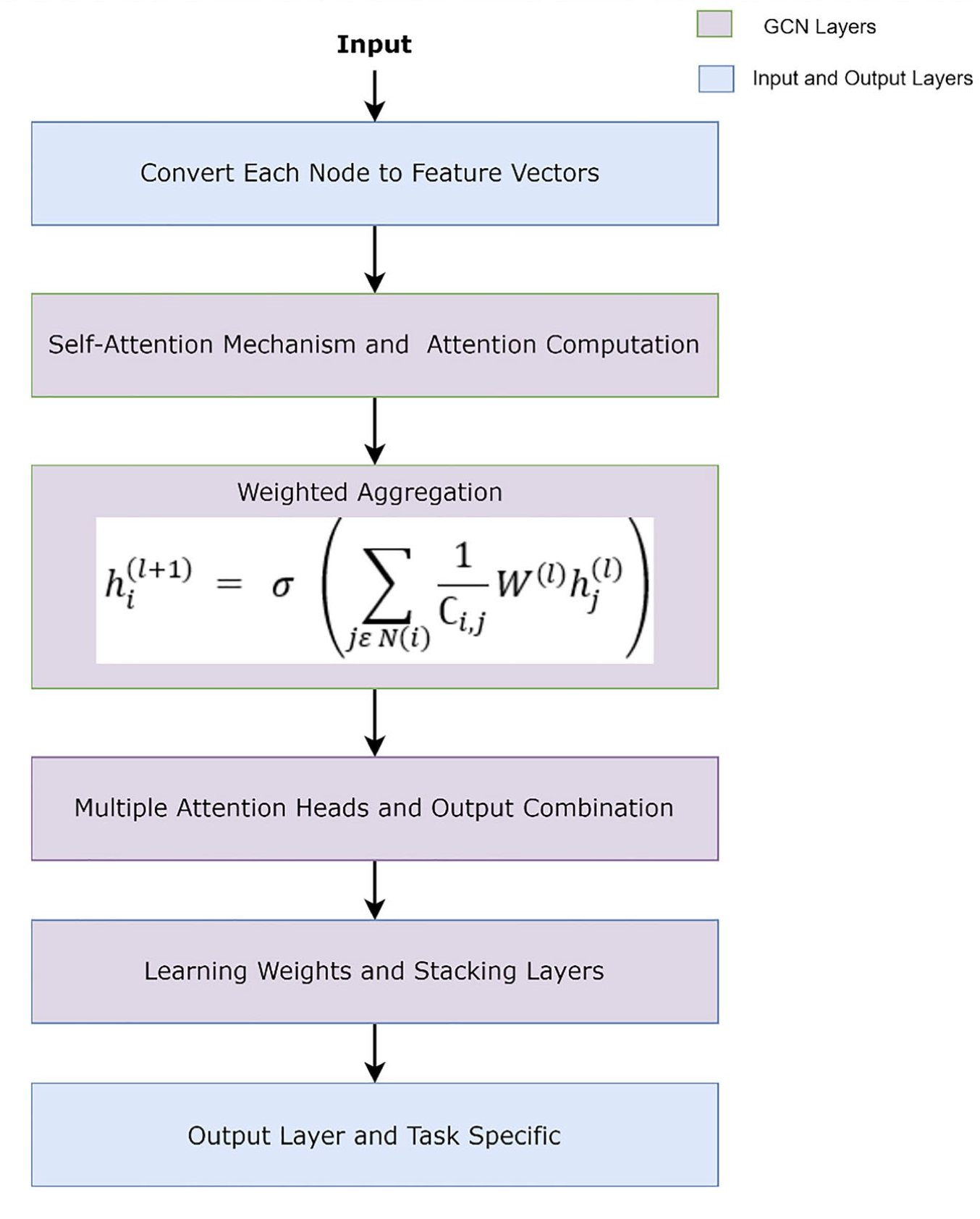
Graph Attention Network
Graph Autoencoders
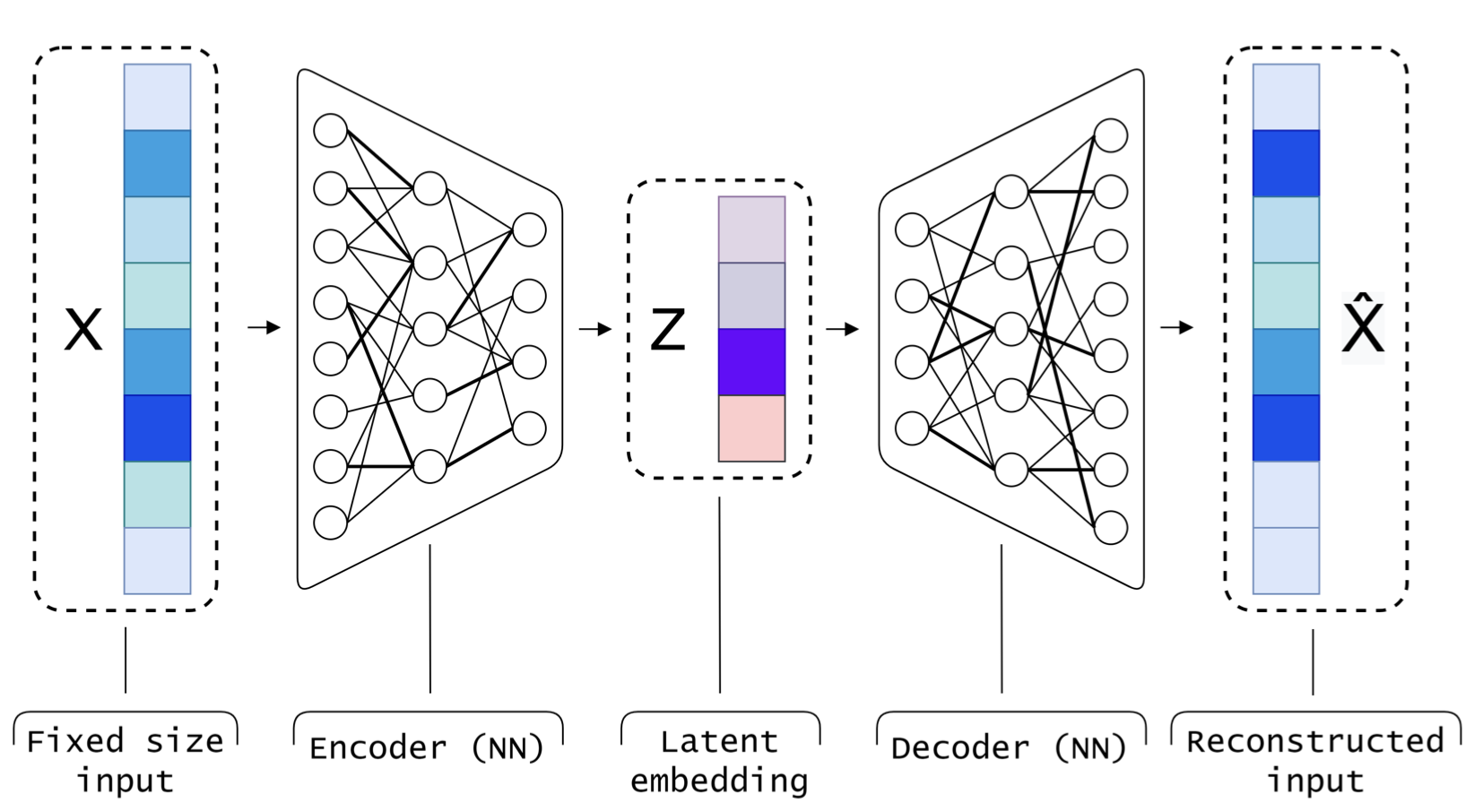
The architecture for a simple traditional standard AE.
Graph Autoencoders
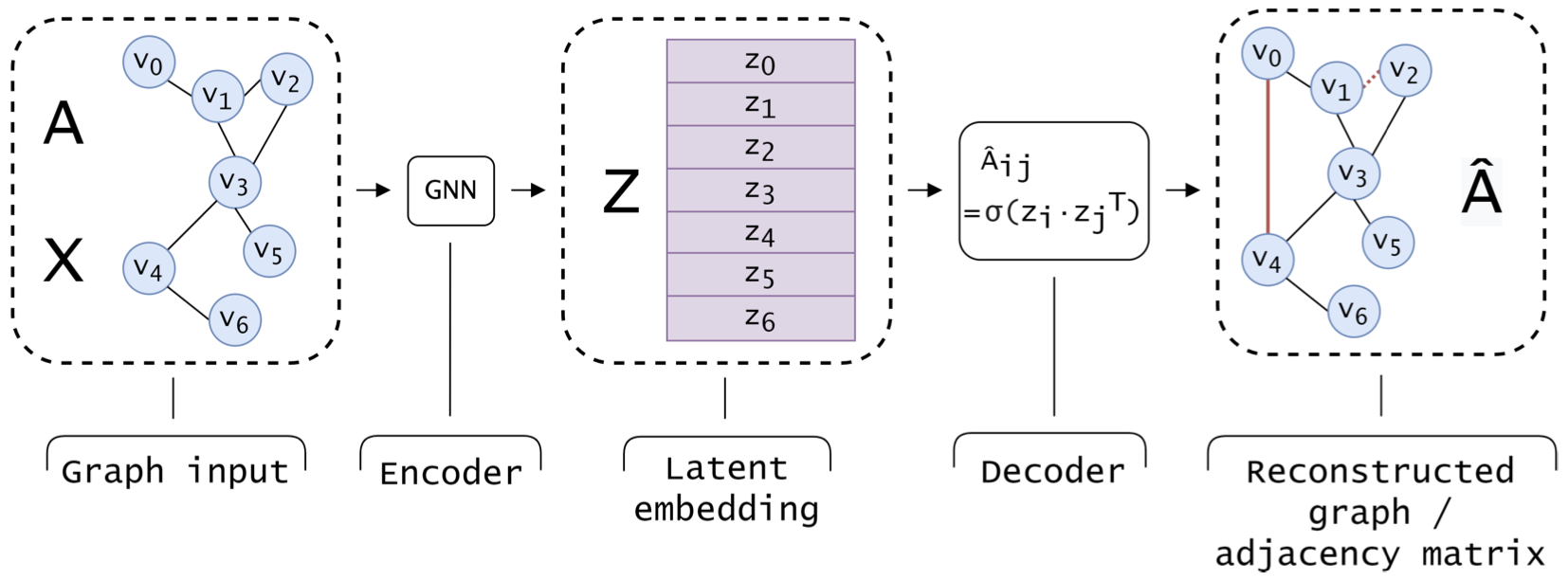
The architecture for a GAE. The input graph is described by the adjacency matrix \(A\) and the vertex feature matrix \(X\).
Variational Graph Autoencoders
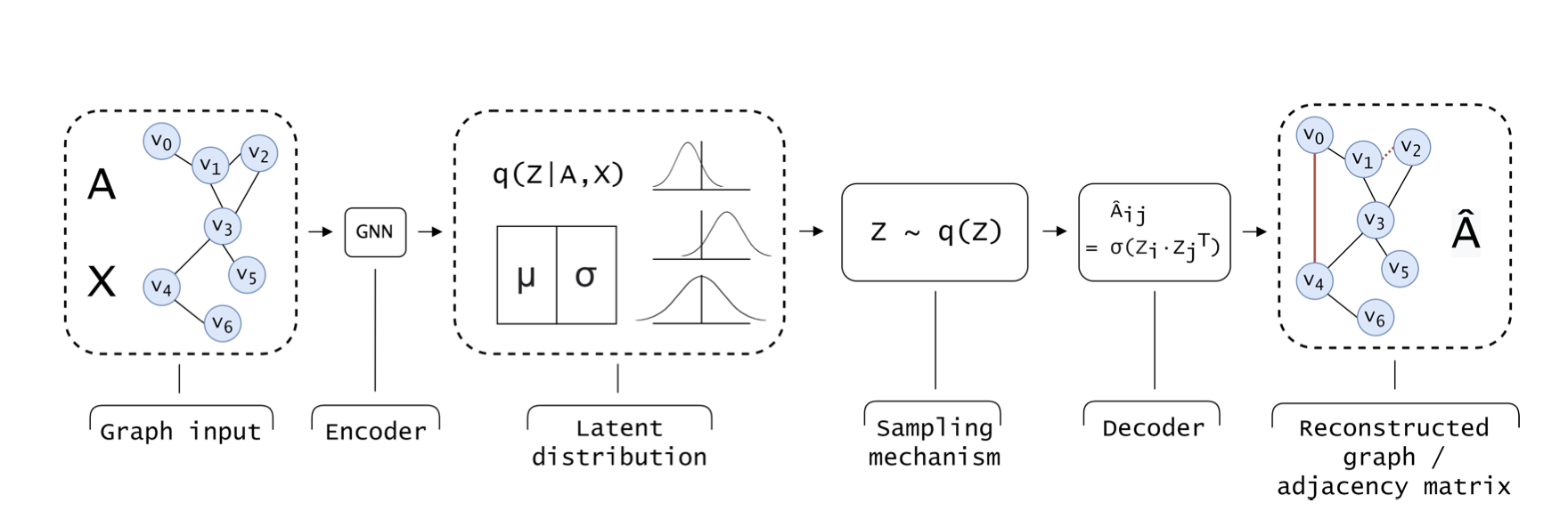
An example of a VGAE. Graph inputs are encoded via a GNN into multivariate Guassian parameters (i.e. mean and variance).
Graph Adversarial Techniques
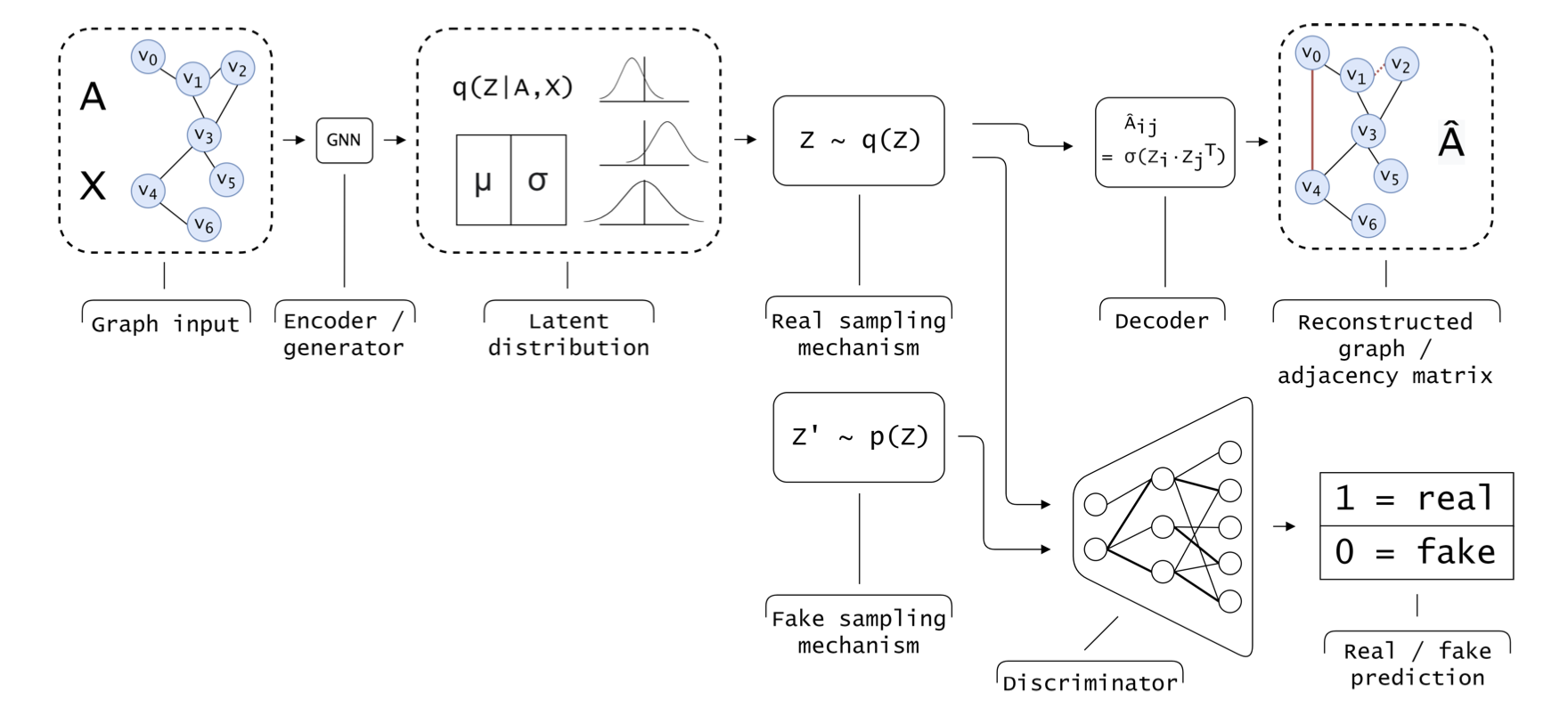
A typical approach to adversarial training with VGAEs.
Graph Attention Network
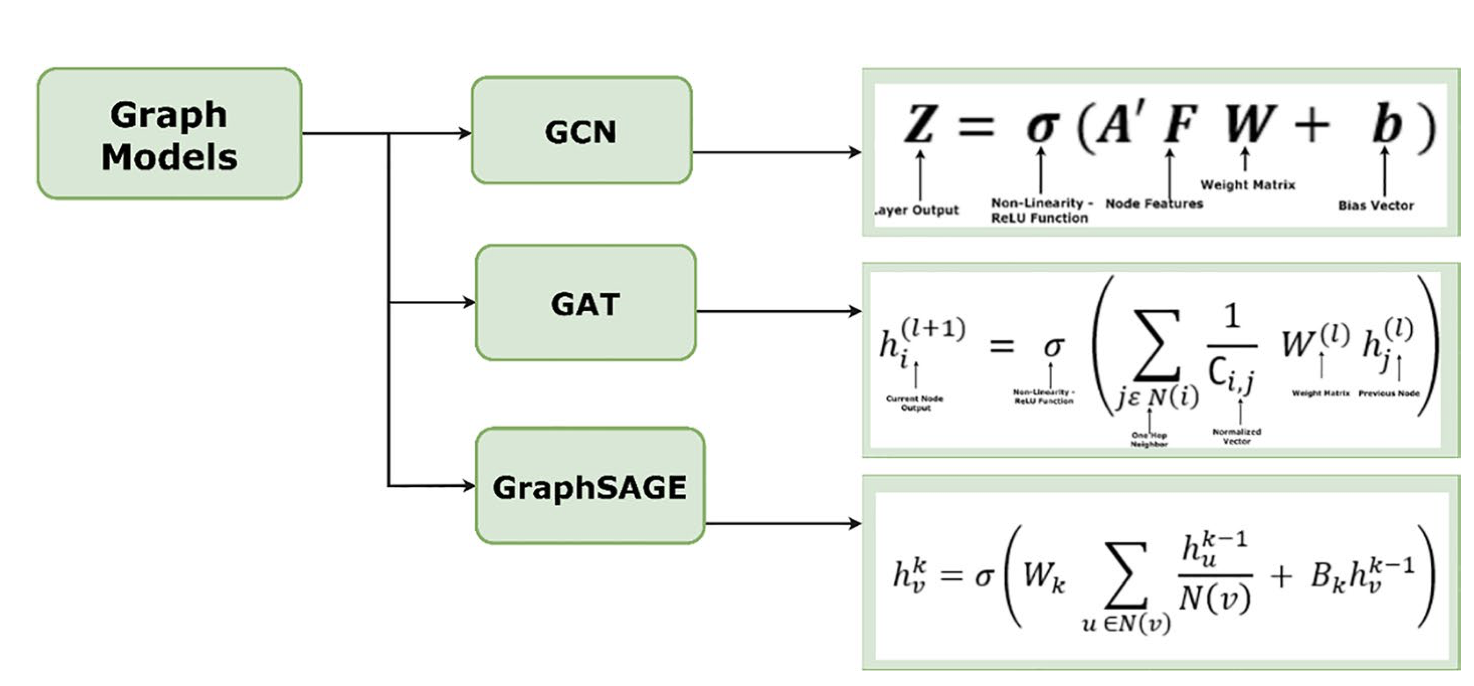
Equations depending on type.
AI timeline: recap
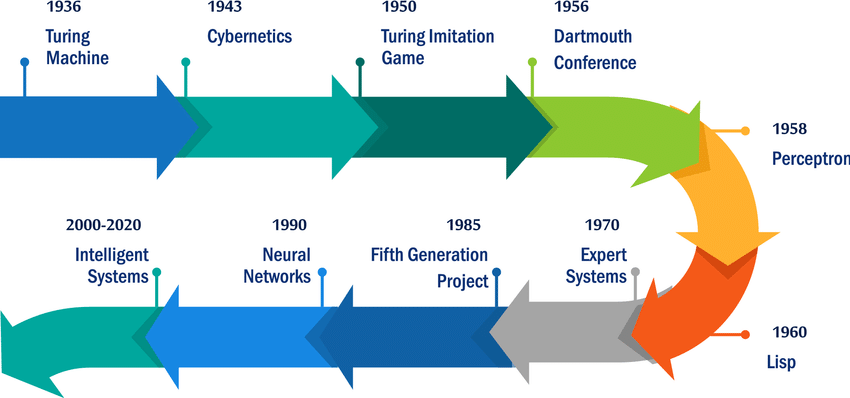
Neurosymbolic AI

Neurosymbolic AI

Neurosymbolic AI
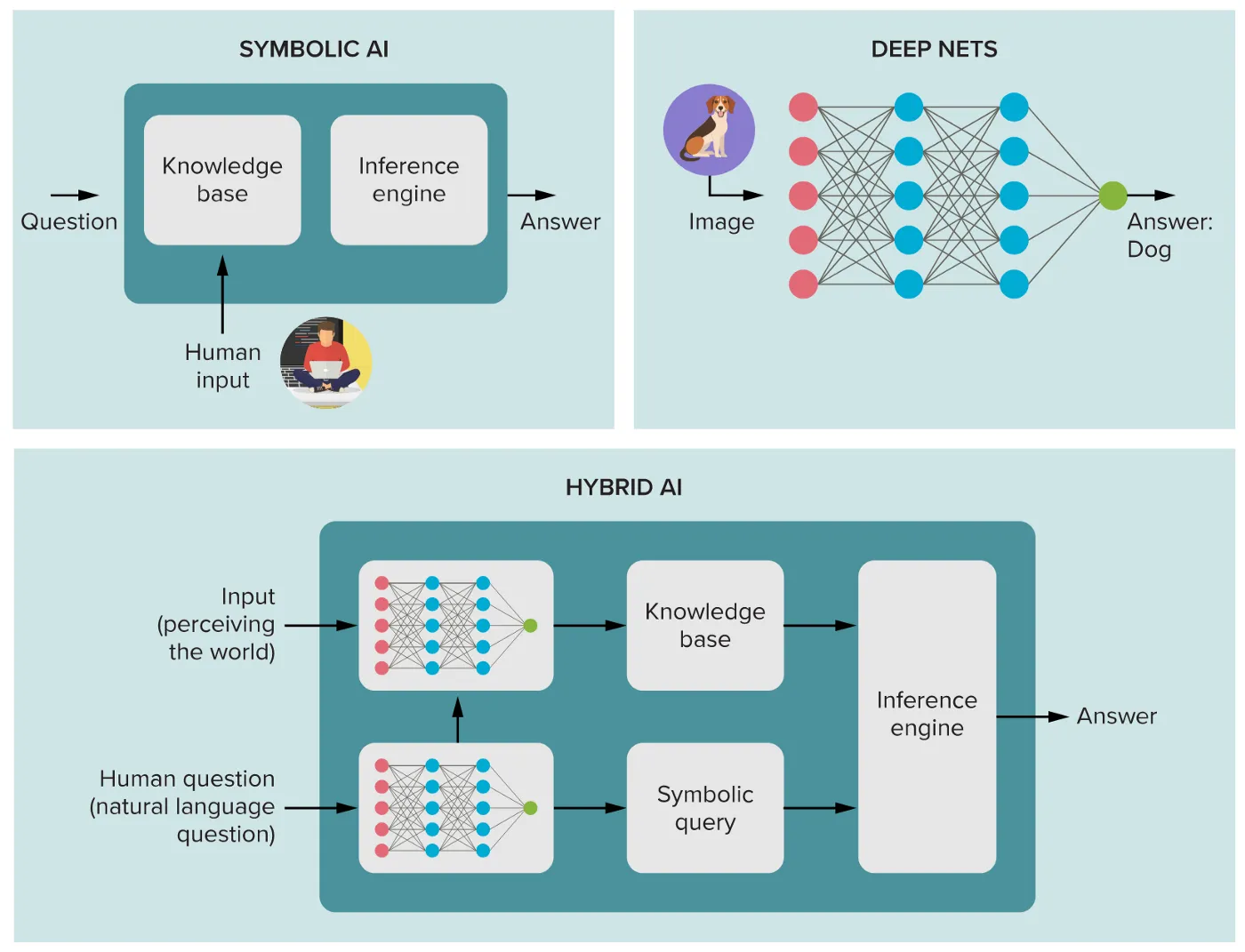
Neurosymbolic AI
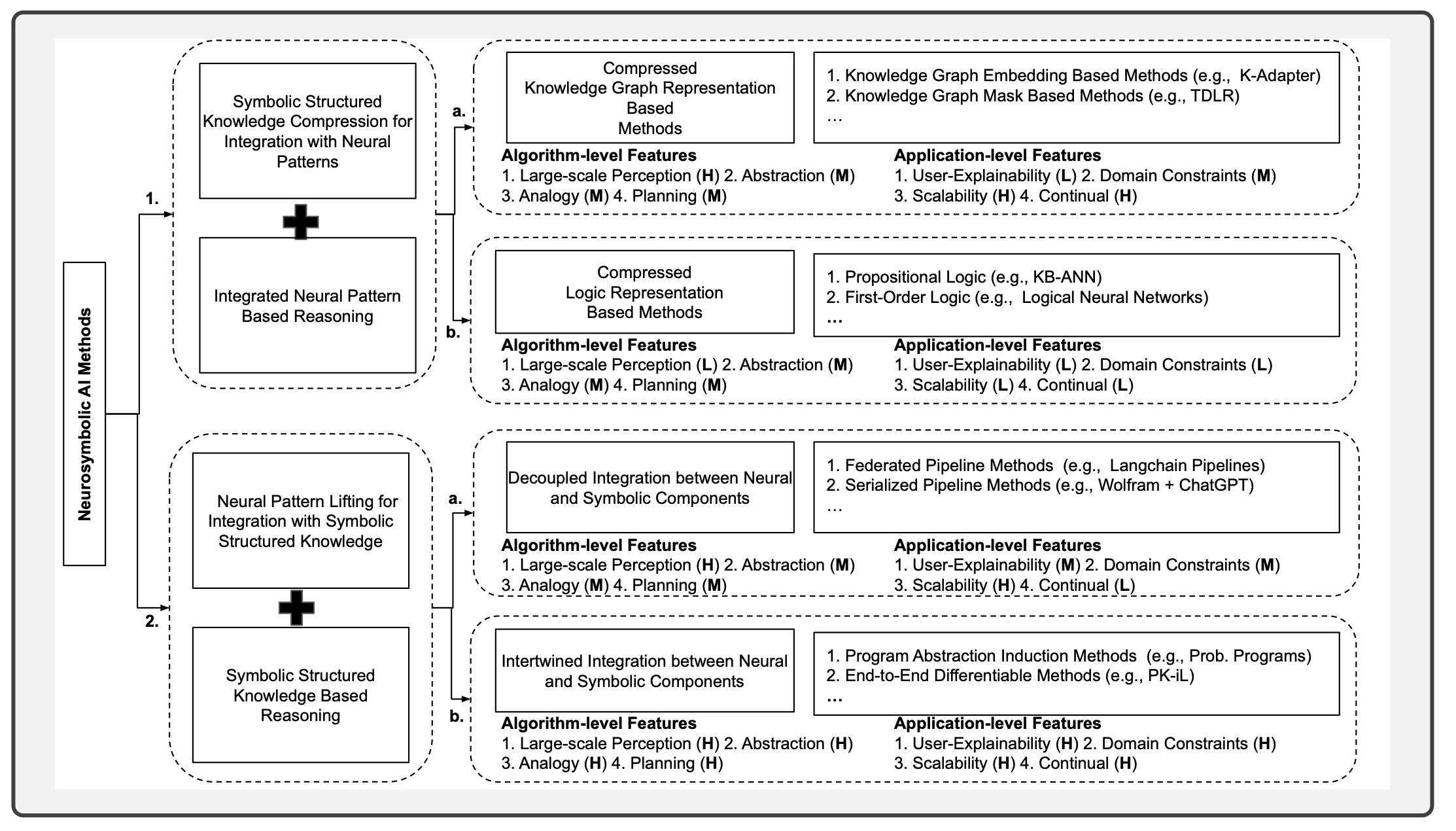
Neurosymbolic AI
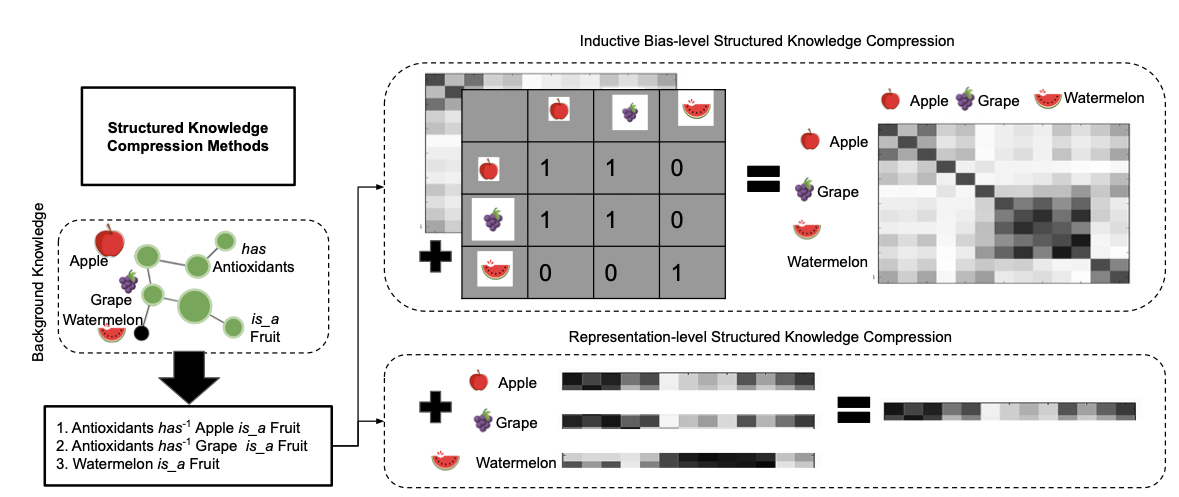
Two methods for compressing knowledge graphs.